读书笔记《distributed-data-systems-with-azure-databricks》第1章Azure数据库简介
Chapter 1: Introduction to Azure Databricks
现代信息系统处理大量数据,并且每天都以指数速度增长。此流量来自不同来源,包括销售信息、交易数据、社交媒体等。组织必须在包括转换和聚合在内的流程中处理这些信息,以开发寻求从这些数据中提取价值的应用程序。
Apache Spark 的开发是为了处理如此大量的数据。 Azure Databricks 构建在 Apache Spark 之上,抽象了实现它的大部分复杂性,并具有与其他 Azure 服务集成所带来的所有好处。本书旨在介绍 Azure Databricks,并探索它在现代数据管道中的应用程序,以在分布式计算环境中从大量数据中转换、可视化和提取见解。
在这个介绍性章节中,我们将探讨以下主题:
- Introducing Apache Spark
- Introducing Azure Databricks
- Discovering core concepts and terminology
- Interacting with the Azure Databricks workspace
- Using Azure Databricks notebooks
- Exploring data management
- Exploring computation management
- Exploring authentication and authorization
这些概念将帮助我们以后了解在 Azure Databricks 中执行作业的所有方面,并在其所有资产之间轻松移动。
Introducing Apache Spark
为了使用 现代消费者可获得的大量信息,创建了 Apache Spark。它是一个分布式的、基于集群的计算系统和一个非常流行的用于大数据的框架,具有提供速度和易用性的功能,并且包括支持以下用例的 API:
- Easy cluster management
- Data integration and ETL procedures
- Interactive advanced analytics
- ML and deep learning
- Real-time data processing
它可以在大型数据集上非常快速地运行,这要归功于其内存处理设计,允许它以很少的读/写磁盘操作运行。它具有类似 SQL 的界面,其面向对象的设计使其非常易于理解和编写代码;它还有一个庞大的支持社区。
尽管有很多好处,Apache Spark 也有其局限性。这些限制包括:
- Users need to provide a database infrastructure to store the information to work with.
- The in-memory processing feature makes it fast to run, but also implies that it has high memory requirements.
- It isn't well suited for real-time analytics.
- It has an inherent complexity with a significant learning curve.
- Because of its open source nature, it lacks dedicated training and customer support.
让我们看看这些问题的解决方案:Azure Databricks。
Introducing Azure Databricks
考虑到这些和其他限制,设计了 Databricks。它是一个基于云的平台 ,它使用 Apache Spark 作为后端,并在 之上构建,添加了包括下列的:
- Highly reliable data pipelines
- Data science at scale
- Simple data lake integration
- Built-in security
- Automatic cluster management
Azure Databricks 由 Microsoft 和启动 Apache Spark 的团队共同打造,还 允许与其他 Azure 产品轻松集成,例如 Blob Storage 和 SQL 数据库,以及 AWS 服务,包括 S3 存储桶。它拥有专门的支持团队,为平台的客户提供帮助。
Databricks 简化了集群的设置和维护,同时支持不同的语言,例如Scala 和 Python,使开发人员能够轻松创建 ETL 管道。由于其类似于笔记本的集成工作区,它还允许数据团队进行实时、跨职能协作,同时保留大量由 Azure Databricks 管理的后端服务。笔记本可用于创建以后可以安排的作业,这意味着本地开发的笔记本可以轻松部署到生产中。使 Azure Databricks 成为任何数据团队的出色工具的其他功能包括:
- A high-speed connection to all Azure resources, such as storage accounts.
- Clusters scale and are terminated automatically according to use.
- The optimization of SQL.
- Integration with BI tools such as Power BI and Tableau.
Examining the architecture of Databricks
每个 Databricks 群集都是一个 Databricks 应用程序,由一组预配置的 VM 组成,这些 VM 作为单个组管理的 Azure 资源运行。您可以指定 在 Databricks 在后端管理其他参数时它将使用的 VM 的数量和类型。托管资源 组已部署并填充了一个名为 VNet 的虚拟网络,这是一个管理资源权限的安全组,和一个存储帐户,除其他外,将用作 Databricks 文件系统。部署完所有内容后,用户可以通过 Azure Databricks UI 管理这些集群。使用的所有元数据都存储在异地复制和容错的 Azure 数据库中。这都可以在 Figure 1.1 中看到:
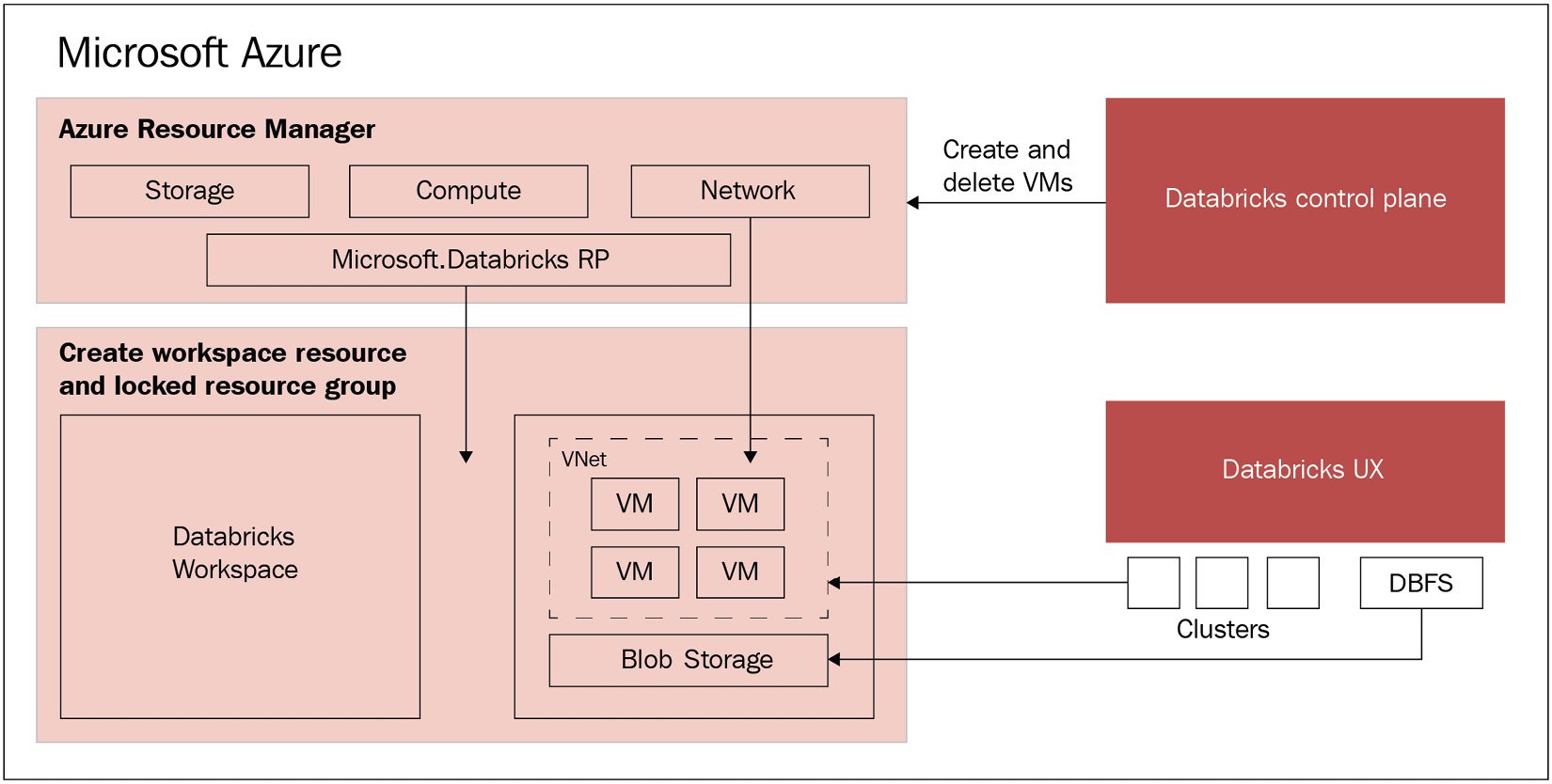
图 1.1 – Databricks 架构
该架构为用户带来的直接好处是与 Azure 无缝连接,使他们能够轻松地将 Azure Databricks 连接到同一 Azure 帐户中的任何资源,并从 Azure 控制中心获得集中管理的 Databricks,无需额外设置。
如前所述,,Azure Databricks 是 Azure 云上的托管 应用程序,由 控制平面和数据平面。控制平面位于 Azure 云上并托管 服务,例如集群管理和作业服务。数据平面是一个组件,包括前面提到的 VNet、NSG 和称为 DBFS 的存储帐户。
您还可以在客户管理的 VNet 中部署数据平面,以允许数据工程团队根据其组织策略构建和保护网络架构。这称为 VNet 注入。
现在我们已经了解了所有内容是如何在幕后布置的,让我们讨论一下和 Databricks 的一些核心概念。
Discovering core concepts and terminology
在深入了解如何创建集群和开始使用 Databricks 的细节之前,我们必须首先熟悉一些概念。这些共同定义了 Databricks 向用户提供的基本工具,并且在 Web 应用程序 UI 以及 的 REST API 中都可用:
- Workspaces: An Azure Databricks workspace is an environment where the user can access all of their assets: jobs, notebooks, clusters, libraries, data, and models. Everything is organized into folders and this allows the user to save notebooks and libraries and share them with other users to collaborate. The workspace is used to store notebooks and libraries, but not to connect or store data.
- Data: Data can be imported into the mounted Azure Databricks distributed filesystem from a variety of sources. This can be uploaded as tables directly into the workspace, from Azure Blob Storage or AWS S3.
- Notebooks: Databricks notebooks are very similar to Jupyter notebooks in Python. They are web interface applications that are designed to run code thanks to runnable cells that operate on files and tables, and that also provide visualizations and contain narrative text. The end result is a document with code, visualizations, and clear text documentation that can be easily shared. Notebooks are one of the two ways that we can run code in Azure Databricks. The other way is through jobs. Notebooks have a set of cells that allow the user to execute commands and can hold code in languages such as Scala, Python, R, SQL, or Markdown. To be able to execute commands, they have to be connected to a cluster, but this connection is not necessarily permanent. This allows an easy way to share these notebooks via the web or in a local machine. Notebooks can be scheduled and triggered as jobs to create a data pipeline, run ML models, or update dashboards:
图 1.2 - Azure Databricks 笔记本。来源:https://databricks.com/wp-content/uploads /2015/10/notebook-example.png
- Clusters: A cluster is a set of connected servers that work together collaboratively as if they are a single (much more powerful) computer. In this environment, you can perform tasks and execute code from notebooks working with data stored in a certain storage facility or uploaded as a table. These clusters have the means to manage and control who can access each one of them. Clusters are used to improve performance and availability compared to a single server, while typically being more cost-effective than a single server of comparable speed or availability. It is in the clusters where we run our data science jobs, ETL pipelines, analytics, and more.
通用集群和作业集群之间存在区别。 通用集群是我们使用笔记本进行协作和交互工作的地方,但 工作集群是我们执行自动和更具体的工作。创建这些集群的方式取决于它是通用集群还是作业集群。前者可以使用 UI、CLI 或 REST API 创建,而后者是使用作业调度程序创建以运行特定作业并在完成时终止。
- Jobs: Jobs are the tasks that we run when executing a notebook, JAR, or Python file in a certain cluster. The execution can be created and scheduled manually or by the REST API.
- Apps: Third-party apps such as Table can be used inside Azure Databricks. These integrations are called apps.
- Apache SparkContext/environments: Apache SparkContext is the main application in Apache Spark running internal services and connecting to the Spark execution environment. While, historically, Apache Spark has had two core contexts available to the user (SparkContext and SQLContext), in the 2.X versions, there is just one – the SparkSession.
- Dashboards: Dashboards are a way to display the output of the cells of a notebook without the code that is required to generate them. They can be created from notebooks:
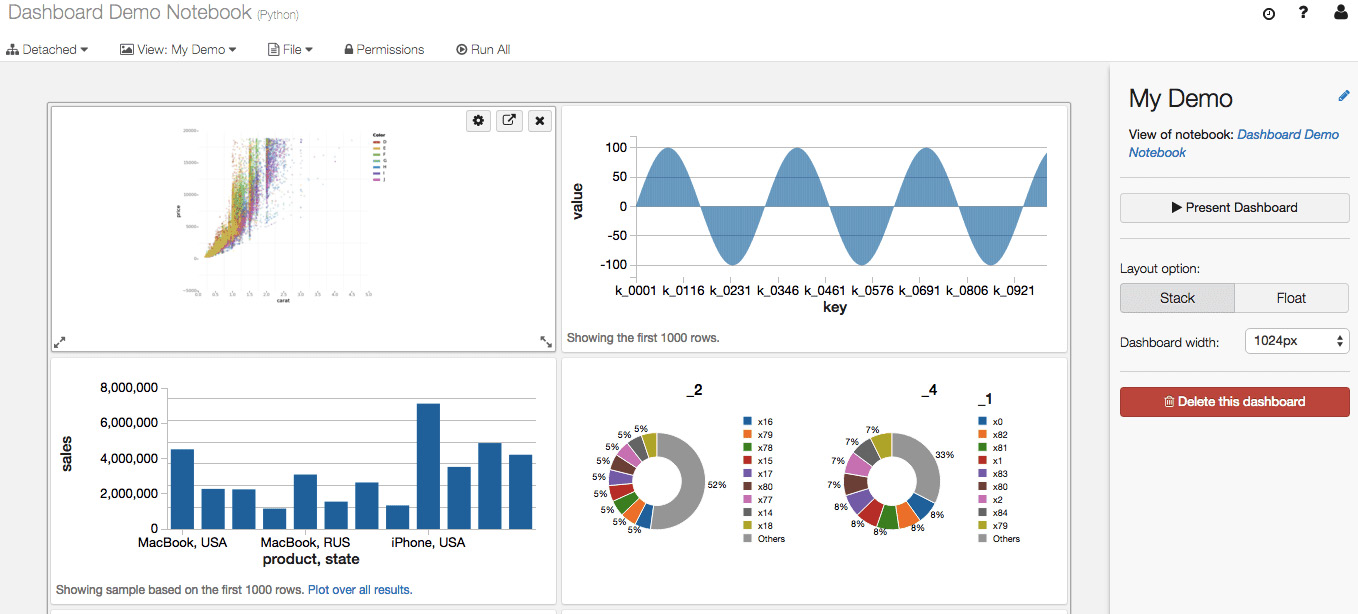
图 1.3 - Azure Databricks 笔记本。来源:https://databricks.com/wp-content /uploads/2016/02/Databricks-dashboards-screenshot.png
- Libraries: Libraries are modules that add functionality, written in Scala or Python, that can be pulled from a repository or installed via package management systems utilities such as PyPI or Maven.
- Tables: Tables are structured data that you can use for analysis or for building models that can be stored on Amazon S3 or Azure Blob Storage, or in the cluster that you're currently using cached in memory. These tables can be either global or local, the first being available across all clusters. A local table cannot be accessed from other clusters.
- Experiments: Every time we run MLflow, it belongs to a certain experiment. Experiments are the central way of organizing and controlling all the MLflow runs. In each experiment, the user can search, compare, and visualize results, as well as downloading artifacts or metadata for further analysis.
- Models: While working with ML or deep learning, the models that we train and use to infer are registered in the Azure Databricks MLflow Model Registry. MLflow is an open source platform designed to manage ML life cycles, which includes the tracking of experiments and runs, and MLflow Model Registry is a centralized model store that allows users to fully control the life cycle of MLflow models. It has features that enable us to manage versions, transition between different stages, have a chronological model heritage, and control model version annotations and descriptions.
- Azure Databricks workspace filesystem: Azure Databricks is deployed with a distributed filesystem. This system is mounted in the workspace and allows the user to mount storage objects and interact with them using filesystem paths. It allows us to persist files so the data is not lost when the cluster is terminated.
本部分重点介绍 Azure Databricks 的核心部分。在下一部分中,您将了解如何通过工作区与 Azure Databricks 交互,这是我们与资产交互的地方。
Interacting with the Azure Databricks workspace
Azure Databricks 工作区是您可以管理笔记本等对象的地方,图书馆和实验。它被组织成文件夹,还提供对数据、集群和作业的访问:
图 1.4 – Databricks 工作区。来源:https://docs.microsoft.com/en-us/azure/数据块/工作区/
可以通过 UI、CLI 或 API 访问 和控制工作区及其资产。 我们将重点介绍如何使用用户界面。
Workspace assets
在 Azure Databricks 工作区中,您可以管理不同的资产,其中大部分我们已经在术语中讨论过。这些资产如下:
在以下部分中,我们将深入了解如何使用文件夹和其他工作区对象。这些对象的管理对于在 Azure Databricks 中运行我们的任务至关重要。
Folders
我们在工作空间内的所有静态 资产都存储在工作空间内的文件夹中。存储的资产可以是笔记本、库、实验和其他文件夹。不同的图标用于表示文件夹、笔记本、目录或实验。点击目录部署项下拉列表:
图 1.5 – 工作区文件夹
单击右上角的下拉箭头将展开菜单项,允许用户对特定文件夹执行操作:
Special folders
Azure Databricks 工作区具有三个您无法重命名或移动到特殊文件夹的特殊文件夹。这些特殊文件夹是,如下:
- Workspace
- Shared
- Users
Workspace root folder
Workspace 根文件夹是一个包含所有静态资产的文件夹。要将 导航到此文件夹,请单击工作区或主页图标,然后单击返回图标:
图 1.7 – 工作区根文件夹
在 Workspace 根文件夹中,您可以选择 Shared 或 Users。前者用于与属于您组织的其他用户共享对象,后者包含特定用户的文件夹。
默认情况下,Workspace 根文件夹及其所有内容可供所有用户使用,但您可以通过启用工作空间 acc< 来控制和管理访问/a>ess 控制和设置权限。
User home folders
图 1.8 – 工作区用户文件夹
如果启用了工作区访问控制,用户文件夹中的对象将对特定用户私有。如果用户的权限被删除,他们仍将能够访问他们的主文件夹。
Workspace object operations
要对工作区对象执行操作,请右键单击该对象或单击对象右侧的下拉图标以部署下拉菜单:
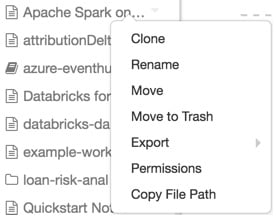
图 1.9 – 对工作区中对象的操作
如果对象是文件夹,则用户可以从此菜单执行以下操作:
- Create a notebook, library, MLflow experiment, or folder.
- Import a Databricks archive.
如果是对象,用户可以选择执行以下操作:
- Clone the object.
- Rename the object.
- Move the object to another folder.
- Move the object to Trash.
- Export a folder or notebook as a Databricks archive.
- If the object is a notebook, copy the notebook's file path.
- If you have Workspace access control enabled, set permissions on the object.
当用户删除一个对象时,该对象会进入垃圾箱文件夹,其中所有内容都会在 30 天后被删除。对象可以从废纸篓文件夹中恢复或永久删除。
现在您已经了解了如何与 Azure Databricks 资产交互,我们可以开始使用 Azure Databricks 笔记本来操作数据,创建ETL、ML 实验等。
Using Azure Databricks notebooks
在本部分,我们将描述在 Azure Databricks 中使用 ith 笔记本的基础知识。
Creating and managing notebooks
在 Azure Databricks 中有 与 笔记本交互的不同方式。我们可以使用 CLI 命令通过 UI 访问它们,也可以通过工作区 API 访问它们。我们现在将专注于 UI:
- By clicking on the Workspace or Home button in the sidebar, select the drop-down icon next to the folder in which we will create the notebook. In the Create Notebook dialog, we will choose a name for the notebook and select the default language:

图 1.10 – 创建一个新笔记本
- Running clusters will show notebooks attached to them. We can select one of them to attach the new notebook to; otherwise, we can attach it once the notebook has been created in a specific location.
- To open a notebook, in your workspace, click on the icon corresponding to the notebook you want to open. The notebook path will be displayed when you hover over the notebook title.
笔记
External notebook formats
Azure Databricks 支持 多种笔记本格式,这些格式可以是其中一种受支持语言(Python、Scala、SQL 和 R)的脚本)、HTML 文档、DBC 档案(Databricks 原生文件格式)、IPYNB Jupyter 笔记本和 R Markdown 文档。
Importing a notebook
我们可以通过单击下拉菜单并选择 Import,将笔记本导入 Azure 工作区。在此之后,我们可以指定一个文件或包含其中一种受支持格式的文件的 URL,然后单击 Import:
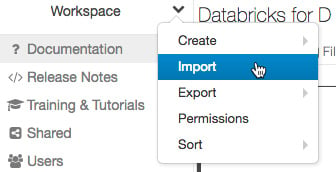
Exporting a notebook
您可以通过单击笔记本工具栏中的文件按钮,然后选择< strong class="bold">导出。请记住,如果您没有清除它们,将包含每个单元格 w的结果。
Notebooks and clusters
为了能够工作,笔记本需要连接到正在运行的集群。我们现在将了解笔记本如何连接到 e 集群以及如何管理这些执行。
Execution contexts
当 笔记本连接到集群时,read-eval-print-loop ( REPL) 环境 已创建。此环境特定于每种受支持的语言,并包含在执行上下文中。
在单个集群中运行的执行上下文限制为 145 个。一旦达到该数量,您就不能再将任何笔记本附加到该集群的 或创建新的执行上下文。
Idle execution contexts
如果执行上下文已超过某个时间阈值而没有任何执行,则将其视为空闲并自动从笔记本中分离。默认情况下,此阈值是 25 小时。
要考虑的一件事是,当群集达到其最大上下文限制时,Azure Databricks 将删除最少 最近使用的空闲执行上下文.这称为驱逐。
如果笔记本从它所连接的集群中被逐出,UI 将显示一条消息:

图 1.12 – 分离的笔记本通知
我们可以在创建集群时配置此行为,也可以通过设置以下内容来禁用它:
Attaching a notebook to a cluster
默认情况下,连接到正在运行的集群的笔记本具有以下 Spark 环境变量:
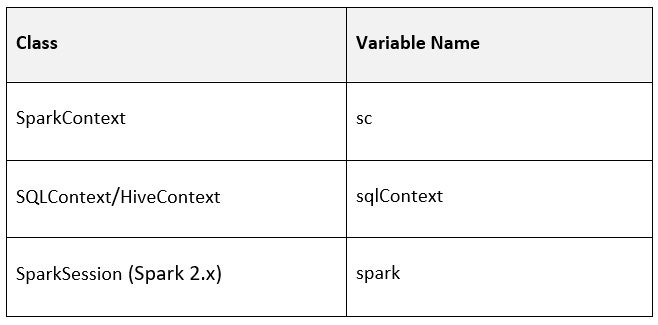
图 1.13 – 显示 Spark 环境变量的表格
我们可以通过在其中一个单元格中运行以下 Python 代码检查在连接笔记本的集群中运行的 Spark 版本:
我们还可以使用以下命令查看当前的 Databricks 运行时版本:
集群和作业 API 需要这些属性才能在它们之间进行通信。
在集群详情页面,Notebooks选项卡会显示所有连接到集群的notebook,以及状态和上次使用的时间:
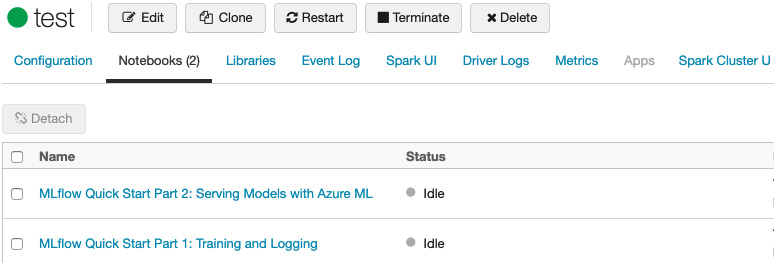
图 1.14 – 连接到集群的笔记本
为了使它们工作,必须将笔记本附加到集群;否则,我们将无法执行其中的代码。
通过单击当前连接的集群并选择 Detach,将笔记本从集群中分离:
图 1.15 – 从集群中分离笔记本
这会导致集群丢失作为变量存储在该笔记本中的所有值。完成工作后,始终将笔记本从集群中分离是一种很好的做法。这可以防止正在运行的集群自动停止,以防 t他的笔记本中运行一个进程(这可能会导致不必要的成本) .
Scheduling a notebook
正如前面提到的,笔记本可以安排定期执行。要安排笔记本作业定期运行,请单击笔记本工具栏右上角的 Schedule 按钮。
A notebook's core functionalities
Notebook toolbar
笔记本有一个工具栏,其中包含有关它所连接的集群的信息,并执行诸如导出笔记本或更改预定义语言等操作(取决于 Databricks 运行时版本) :

图 1.16 – 笔记本工具栏
此工具栏可帮助我们浏览笔记本中的常规选项,并让我们更轻松地管理我们与计算集群的交互方式。
Cells
图 1.17 – 执行单元
在单元格的左上角,在单元格操作中,您有以下选项:运行此单元格、仪表板 、编辑、隐藏、和删除:
- You can use the Undo keyboard shortcut to restore a deleted cell by selecting Undo Delete Cell from Edit.
- Cells can be cut using cell actions or the Cut keyboard shortcut.
- Cells are added by clicking on the Plus icon at the bottom of each cell or by selecting Add Cell Above or Add Cell Below from the cell menu in the notebook toolbar.
Running cells
可以从单元格操作工具栏运行特定单元格。要运行多个单元格,我们可以选择 Run all、all above 或 all below 。我们也可以选择Run All、 Run All Above或Run All below 从笔记本工具栏中的 运行 选项。请记住,Run All below包括您当前所在的单元格。
Default language
每个笔记本的默认 语言显示在笔记本名称旁边的括号中,在以下示例中为 SQL:

图 1.18 – 单元格默认语言
如果单击括号中的语言名称,将出现一个对话框,您可以在其中更改笔记本的默认语言:
图 1.19 – 更改单元格的默认语言
当默认语言更改时,魔术命令将被添加到不是新默认语言的单元格中,以保持它们的工作。
也可以使用魔术命令在每个单元格中指定语言。语言规范支持四种魔术命令:%python、%r、%scala< /code> 和 %sql。
还有还有其他神奇的命令,比如%sh,可以让你运行shell代码; %fs 使用 dbutils 文件系统命令;和 %md 来指定 Markdown,用于包含注释和文档entation。我们将更详细地讨论这一点。
Including documentation
Markdown 是一种具有纯文本格式语法的轻量级标记语言,通常用于 格式化自述文件,它允许使用纯文本创建富文本。
正如我们之前所见,Azure Databricks 允许通过使用 %md 魔术命令 将 Markdown 用于文档。然后将标记呈现为具有所需格式的 HTML。例如,下面的代码用于将文本格式化为标题:
它呈现为 HTML 标题:

图 1.20 – Markdown 标题
文档块是 Azure Databricks 笔记本最重要的功能之一。它们使我们能够说明我们代码的 p 目的以及我们如何解释我们的结果。
Command comments
用户可以通过突出显示代码并单击单元格右下角的注释按钮来向代码的特定部分添加注释:

图 1.21 – 选择一部分代码
这将提示一个文本框,我们可以在其中放置评论以供其他用户查看。之后,注释的文本将突出显示:

图 1.22 – 评论选择
评论使我们能够提出更改或要求提供有关笔记本特定部分的信息,而无需干预内容。
Downloading a cell result
您可以通过单击单元格底部的下载按钮将表格结果从单元格下载到本地计算机:
图 1.23 – 从单元格下载完整结果
默认情况下,Azure Databricks 限制您查看 1,000 行 DataFrame,但如果存在更多数据,我们可以单击下拉 图标并选择 下载完整结果以查看更多信息。
Formatting SQL
格式化 SQL 代码可能会占用大量时间,并且跨笔记本执行标准可能很困难。
Azure Databricks 具有在笔记本单元格中格式化 SQL 代码的功能,以减少格式化代码所需的时间,并有助于在所有环境中应用相同的编码标准笔记本。要将自动 SQL 格式应用于单元格,您可以从单元格上下文菜单中选择它。这仅适用于 SQL 代码单元:
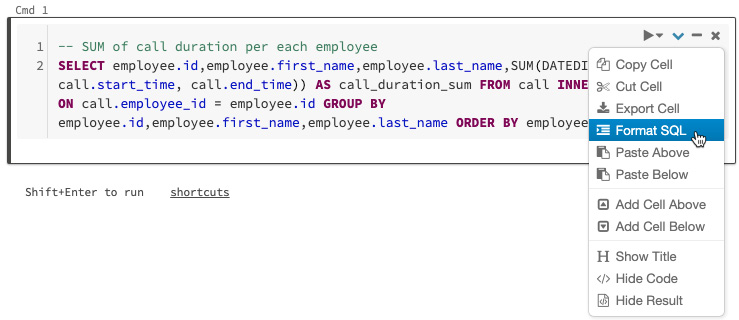
图 1.24 – SQL 代码的自动格式化
应用 SQL 代码的自动格式化功能可以提高我们代码的可读性,并减少由于格式错误而可能出现的错误。
Exploring data management
在本节中,我们将深入探讨如何在 Azure Databricks 中管理数据,以便执行分析、创建 ETL 管道、训练 ML 算法等。首先,我们将简要介绍 Azure Databricks 中的数据类型。
Databases and tables
在 Azure Databricks 中,数据库由表组成;结构化数据的表集合。用户可以使用这些表,使用 Apache Spark DataFrames 支持的所有操作,并使用 Spark API 和 Spark SQL 查询表。
这些表可以是全局的或本地的,可供所有集群访问。全局表存储在 Hive 元存储中,而本地表则不是。
可以使用 DBFS 中的文件或来自所有受支持数据源的数据来填充表。
Viewing databases and tables
可以通过单击侧边栏中的数据 图标按钮查看与您当前使用的集群相关的表。 Databases 文件夹将显示每个选定数据库中的表列表:
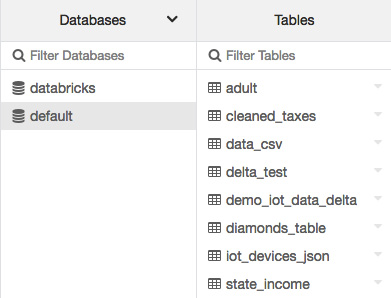
图 1.25 – 默认表
用户可以通过单击 Databases 文件夹顶部的下拉图标并选择集群来选择不同的集群:
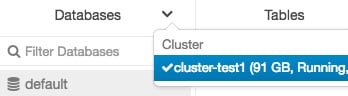
图 1.26 – 选择不同集群中的数据库
我们可以在一个集群上有几个查询,每个查询都有自己的文件系统。当我们在笔记本中引用数据时,这一点非常重要。
Importing data
可以使用 UI 将本地文件上传到 Azure Databricks 文件系统。
可以使用 UI 将数据导入 Azure Databricks DBFS 以存储在 FileStore 中。为此,您可以转到 Upload Data UI 并选择要上传的文件以及 DBFS 目标目录:
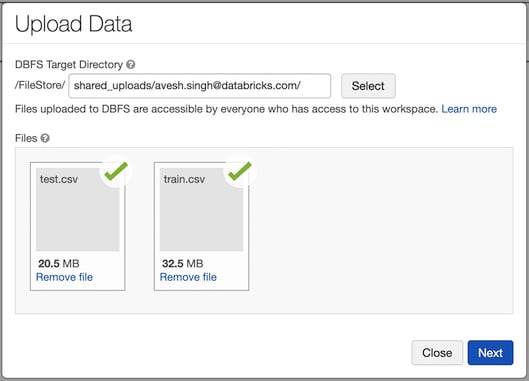
图 1.27 – 上传数据 UI
将数据上传到表格的另一个可用选项是使用 创建表格 UI,可在 Import &工作区中的探索数据框:
图 1.28 – 在 Import & 中创建表格 UI探索数据
对于生产 环境,建议使用 DBFS CLI、DBFS API、 或 Databricks 文件系统实用程序(dbutils.fs)。
Creating a table
用户可以使用 SQL 以编程方式创建表,也可以通过 UI 创建表,其中 创建全局表。通过点击侧边栏中的数据图标按钮,您可以选择Databases右上角的添加数据,然后表格显示:
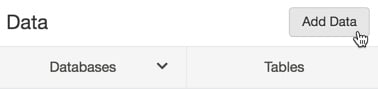
图 1.29 – 添加数据以创建新表
在此之后,您将看到一个对话框,您可以在其中上传文件以创建新表,选择数据源和集群,将其上传到 DBFS 的路径,还可以预览桌子:
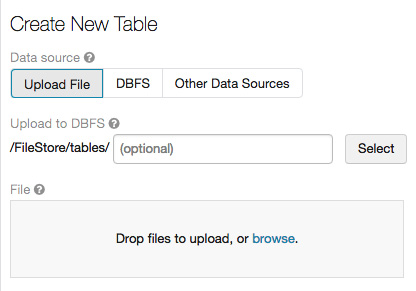
图 1.30 – 创建一个新的表格 UI
通过 UI 或 添加数据 选项创建 表是众多选项中的两个 ns 我们必须将数据引入 Azure Databricks。
Table details
用户可以通过单击Tables文件夹中的表格名称来预览表格的内容。这将显示表的视图,我们可以在其中看到表模式和包含在其中的数据示例:
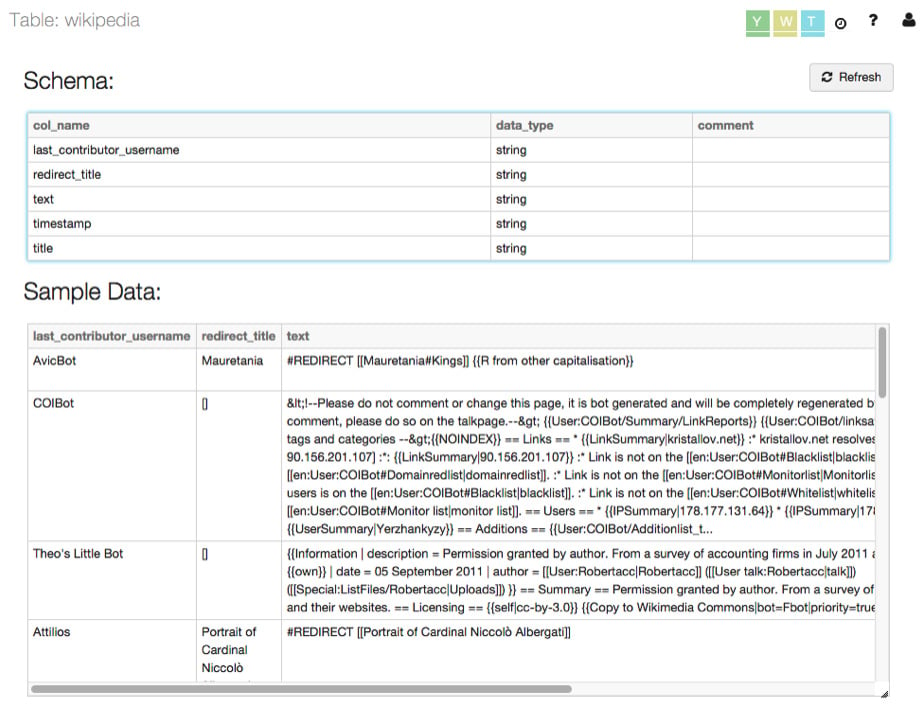
图 1.31 – 表格详情
这些表详细信息允许我们提前进行n 次转换,以使数据符合我们的需求。
Exploring computation management
在本节中,我们将简要介绍如何管理 Azure Databricks 集群,这是我们所有操作的计算骨干。我们将描述如何显示集群信息,以及如何编辑、启动、终止、删除和监控日志。
Displaying clusters
要在工作区中显示集群,请单击侧栏中的集群图标。您将看到 Cluster 页面,该页面在两个选项卡中显示集群:All-Purpose Clusters 和 作业集群:
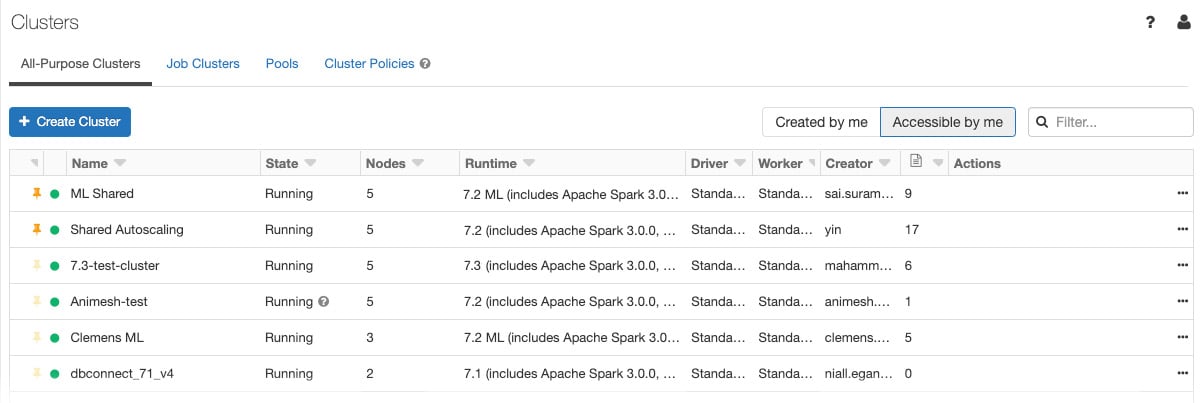
图 1.32 – 集群详情
除了常见的集群信息之外,All-Purpose Clusters 还显示了有关连接到它们的笔记本数量的信息。
可以在 all-purpose 集群的最右侧访问终止、重新启动、克隆、权限和删除等操作:
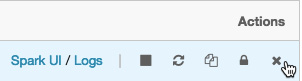
图 1.33 – 对集群的操作
Starting a cluster
除了创建新集群外,您还可以启动之前终止的集群。这使您可以使用其原始配置重新创建先前终止的集群。可以从 Cluster 列表中启动集群,在笔记本的集群详细信息页面上的集群图标附加下拉列表中:
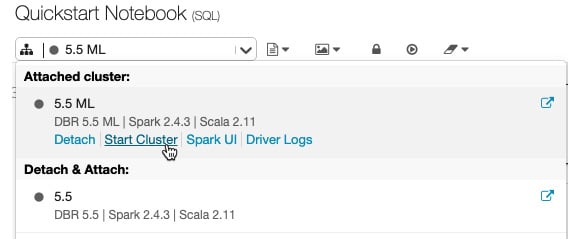
图 1.34 – 从笔记本工具栏启动集群
每个集群都是唯一标识的,当你启动一个终止的集群时,Azure Databricks 会自动ally 安装库并将笔记本重新附加到它。
Terminating a cluster
要保存 资源,您可以终止集群。存储已终止集群的配置,以便以后可以重用。
集群可以手动终止,也可以在指定的不活动时间后自动终止:
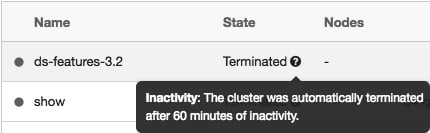
图 1.35 – 终止的集群
Deleting a cluster
删除 集群会终止集群并删除其配置。请谨慎使用,因为此操作无法撤消。
要删除集群,请单击 Job Clusters 或 All-Purpose Clusters 选项卡上集群操作中的删除图标:

图 1.36 – 从 Job Clusters 选项卡中删除一个集群
您还可以调用永久 delete API 端点以编程方式删除集群。
Cluster information
Spark作业的详细信息显示在Spark UI中,可以从集群列表或集群详情页面访问。 Spark UI 显示活动集群和终止集群的集群历史记录:
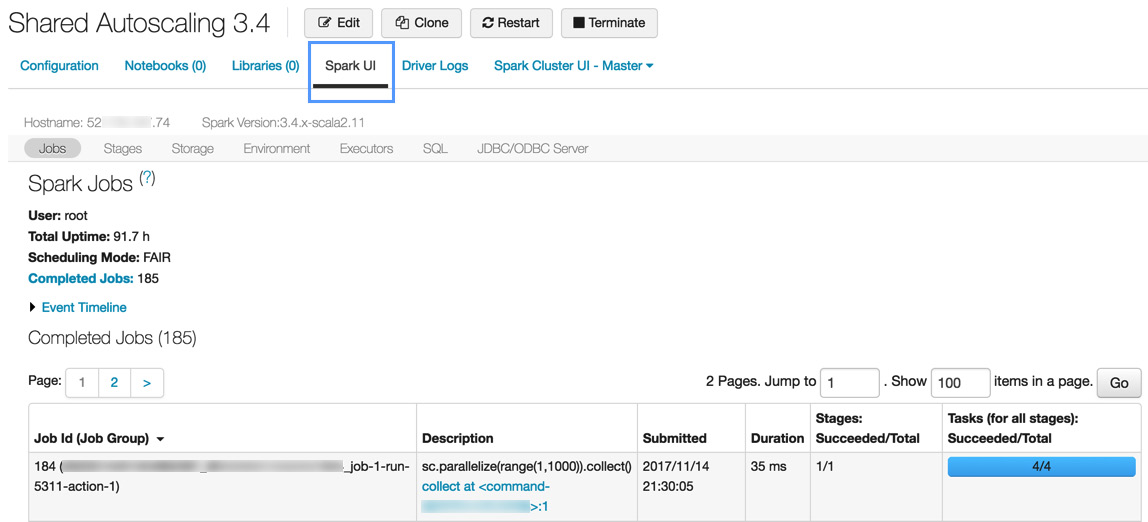
图 1.37 – 集群信息
集群信息使我们能够深入了解我们的流程并识别任何可能的瓶颈,这可以指出我们可能优化机会。
Cluster logs
Azure Databricks 提供三种集群相关活动的日志记录:
- Cluster event logs for life cycle events, such as creation, termination, or configuration edits
- Apache Spark driver and worker logs, which are generally used for debugging
- Cluster init script logs, valuable for debugging init scripts
Azure Databricks 提供群集事件日志,其中包含有关手动或自动触发的生命周期事件的信息,例如创建和配置编辑。还有 Apache Spark 驱动程序和工作程序的日志,以及集群初始化脚本日志。
事件存储 60 天,这与 Azure Databricks 中的其他数据保留时间相当。
要查看集群事件日志,请单击侧边栏的 Cluster 按钮,单击集群名称,然后最后单击 Event Log 标签:
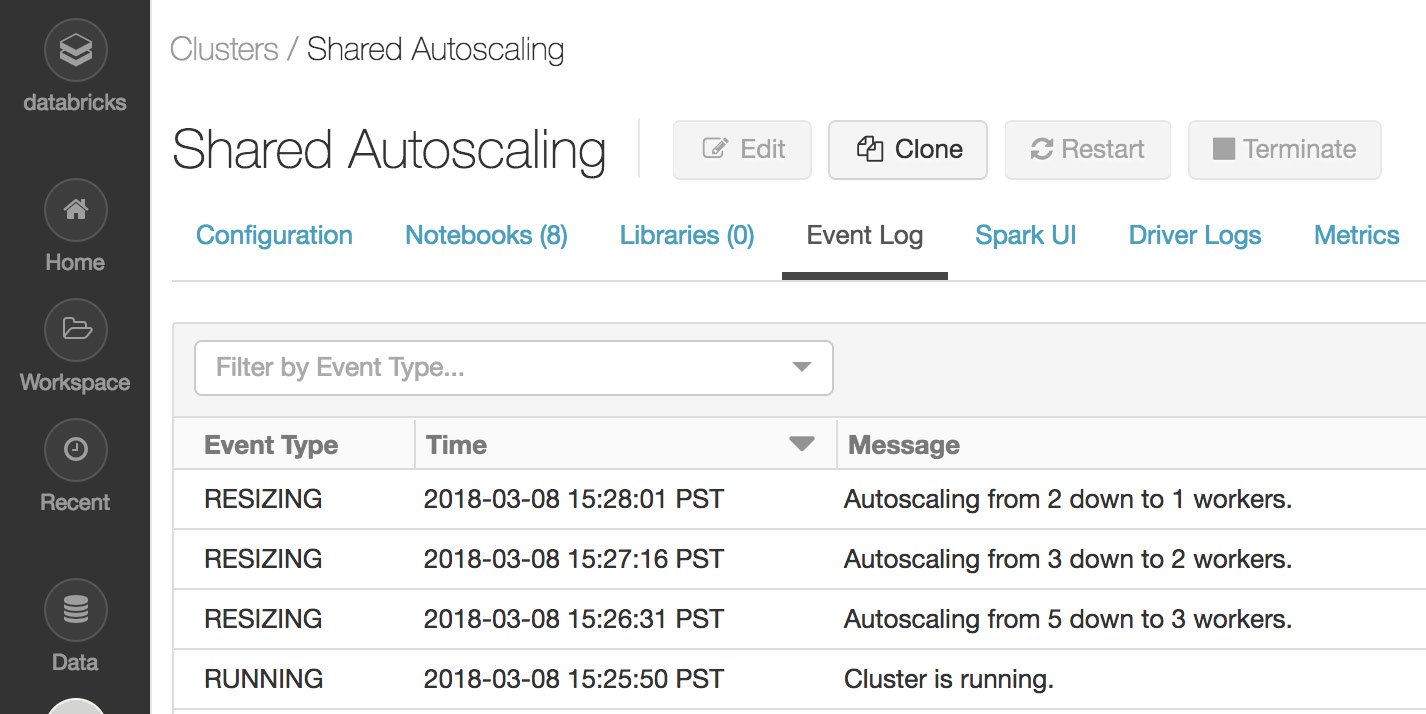
图 1.38 – 集群事件日志
集群事件为我们提供了关于在我们的作业执行期间在集群上执行的操作的具体信息。
Exploring authentication and authorization
Azure Databricks 允许用户执行访问控制以管理对工作区对象、集群、池和数据表的访问。管理员用户管理 access 控制列表以及具有委派权限的用户。
Clustering access control
默认情况下,在 Azure Databricks 中,所有用户都可以创建或修改集群。在使用集群访问控制之前,管理员用户必须启用它。在此之后,有两种集群权限,分别是:
- The Allow Cluster Creation permission allows the creation of clusters.
- Cluster-level permissions allow you to manage clusters.
启用集群访问控制后,只有具有Can Manage perm问题的管理员和用户才能配置、创建、终止或删除集群.
Configuring cluster permissions
集群访问控制可以通过点击侧边栏的cluster按钮来配置,在操作选项,选择权限按钮。这将提示一个权限对话框,用户可以在其中执行以下操作:
- Apply granular access control to users and groups using the Add Users and Groups options.
- Manage granted access for users and groups.
这些选项在 图 1.39 中可见:
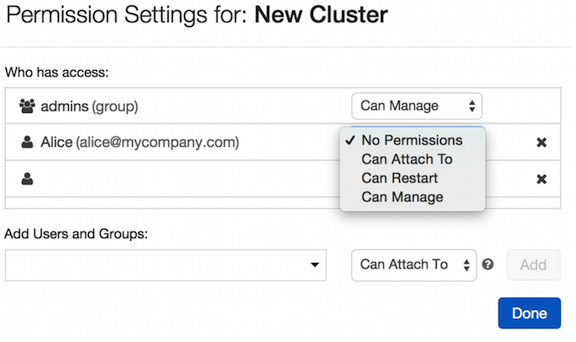
图 1.39 – 管理集群权限
Folder permissions
文件夹有 五级权限:无权限、读取、运行、编辑和管理。任何笔记本或 experiment 都将继承包含它们的文件夹权限。
Default folder permissions
- Objects in the Shared folder can be managed by anyone.
- Users can manage objects created by themselves.
当没有工作区访问控制时,用户只能编辑其 Workspace 文件夹中的项目。
- Only admins can create items in the Workspace folder, but users can manage existing items.
- Permissions applied to a folder will be applied to the items it contains.
- Users keep having Manage permission to their home directories.
了解这些权限有助于我们提前了解这些策略中可能发生的变化会如何影响用户与组织数据的交互方式。
Notebook permissions
笔记本与文件夹具有相同的五个权限n 级:无权限, 读取、运行、编辑和管理。
Configuring notebook and folder permissions
用户可以通过单击笔记本上下文栏中的权限按钮来配置笔记本权限。选择文件夹和然后点击下拉菜单中的Permissions:

图 1.40 – 笔记本权限
从那里,您可以向用户或组授予权限以及编辑现有权限:
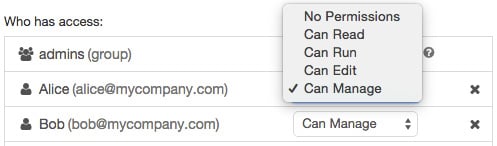
图 1.41 – 笔记本的访问控制
Access 可以很容易地应用对笔记本的控制 in 通过选择这种方式下拉菜单中的选项之一。
MLflow Model permissions
您可以为在MLflow模型注册表中注册的MLflow模型分配六个权限级别:无权限、读取、编辑它、管理暂存版本、管理生产版本和管理。
Default MLflow Model permissions
- Models in the registry can be created by anyone.
- Administrators can manage any model in the registry.
当没有工作区访问控制时,用户可以管理注册表中的任何模型。
启用工作区访问控制后,存在以下权限:
- Users can manage only the models they have created.
- Only administrators can manage models created by other users.
T这些选项适用于在 Azure Databricks 中创建的 MLflow 模型。
Configuring MLflow Model permissions
要记住的一件事是,只有管理员属于具有 Manage 权限组的管理员,而其余用户属于 all用户组。
MLflow模型权限可以通过点击侧边栏的模型图标,选择模型名称,点击模型名称右侧的下拉图标,最后修改权限选择权限。这将向我们显示一个对话框,我们可以从中选择特定用户或组并添加特定权限:

图 1.42 – MLflow 权限
您可以通过从 Permission 下拉菜单中选择新权限来更新用户或组的权限:
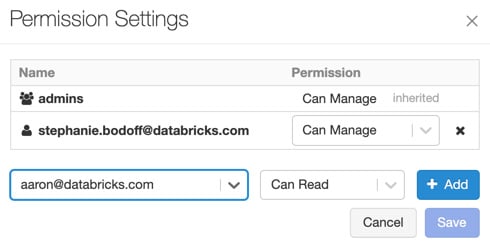
图 1.43 – MLflow 访问管理
通过选择其中一个选项,我们可以控制 MLflow 实验如何与我们的数据交互,以及哪些用户可以创建使用它的模型。
Summary
在本章中,我们尝试涵盖 Azure Databricks 工作原理的所有主要方面。我们发现的一些内容包括如何创建笔记本来执行代码、如何导入数据以供使用、如何创建和管理集群等等。这一点很重要,因为在组织内的 Azure Databricks 中创建 ETL 和 ML 实验时,除了如何在笔记本中编写 ETL 之外,我们还需要知道如何管理所需的数据和计算资源、如何共享资产以及如何管理他们每个人的权限。
在下一章中,我们将应用这些知识更详细地探索如何创建和管理在 Azure Databricks 中处理数据所需的资源,并了解更多关于自定义 VNet 以及我们为与之交互而拥有的不同替代方案,通过 Azure Databricks UI 或 CLI 工具。