读书笔记《functional-kotlin》在Kotlin中使用溪流
所以,我们正在逐步完成这本书。在本章中,我们将介绍 Kotlin 中的 Streams 以及如何使用它们。
Streams 最初是从 Java 8 开始在 Java 中引入的。Kotlin 中的 Streams API 几乎与 Java API 相同,但包含一些小的添加和扩展功能。
这是我们将在本章中介绍的内容:
- Introduction to Streams
- Collections versus Streams
- Streams versus Observable (ReactiveX-RxKotlin/RxJava)
- Working with Streams
- Different ways to create Streams
- Collecting Streams
那么,让我们开始吧。
正如我们前面提到的,Streams 最早是从 Java 8 引入的。从 Java 8 开始,Java 开始更加关注函数式编程并开始逐渐添加功能特性。
另一方面,Kotlin 从一开始就开始添加功能特性。 Kotlin 添加了功能特性和接口。使用 Java 时,只有使用 Java 8 及更高版本才能使用 Streams,但使用 Kotlin,即使使用 JDK 6,您仍然可以使用 Streams。
那么,什么是流?您可以将 Streams 视为一系列元素之上的抽象层,以执行聚合操作。使困惑?我们举个代码例子,然后试着理解:
fun main(args: Array<String>) {
val stream = 1.rangeTo(10).asSequence().asStream()
val resultantList = stream.skip(5).collect(Collectors.toList())
println(resultantList)
}
输出如下:

在前面的程序中,我们所做的是创建一个 IntRange value,然后从中创建一个 Sequence value,然后然后从中获取 stream value。然后我们跳过前五个项目,然后将其收集回 List 实例。我们将在本章后面的代码中详细了解前面代码中使用的所有函数。
读到这里,您可能认为我们在该程序中执行的所有操作都可以通过 Kotlin 中的 Collections 本身来实现,那么我们为什么要使用 Streams?要回答这个问题,我们首先应该了解 Streams 和 Collections 之间的区别。因此,让我们看一下由 Collections 和 Streams 之间的差异组成的以下列表:
- As the definition of Collections says, a Collection is a data structure which stores and lets you work with a group of data. Streams, on the other hand, aren't data structures and don't store anything; they work like a pipeline or IO channel, which fetches data from its source on demand.
- Every data structure must have a finite size limit, and the same applies to Collections as well. But, as Streams are not data structures, they don't need to have any specific size limit.
- While accessing elements of a Collection directly, you can do it any time, even for the same position, without the requirement of recreating the Collection. But when working with Streams, elements of a Stream are only visited once during the life of a Stream. Like an iterator, a new Stream must be generated to revisit the same elements of the source.
- The Collection API constructs objects in an eager manner, always ready to be consumed. The Stream API creates objects in a lazy, on-demand basis.
- The Collection API is used for storing data in different kinds of data structures. The Stream API is used for the computation of data on a large set of objects.
因此,这些是 Collection API 和 Stream API 之间非常基本的区别。乍一看,Streams 看起来像 RxKotlin,Observables 提供了一种消费数据的方式,但 Streams 和 Observables。以下是 Streams 和 Observables 之间的区别:
- The first notable difference is that Streams are pull-based, and Observables are push-based. This may sound too abstract, but it has significant consequences that are very concrete.
- With Observables, it's easy to change threads or specify thread pools for a chain with ease, thanks to Schedulers. But, with Streams, it's a bit tricky.
- Observables are synchronized all the way through. This spares you from checking all the time whether these basic operations are thread safe.
- One more significant difference is that Observables have a lot more functional interfaces than the Streams API, which makes Observables easy to use with a lot of options to accomplish a certain task.
因此,我们了解到 Streams 不是数据结构,而是像数据源(可能是 Collections 或其他任何东西)之上的抽象层,即使 Streams 以惰性、按需的方式构造对象,它们也是仍然基于拉动并在其中使用循环。
因此,我们学习了很多关于 Streams 的理论,并且我们还了解到 Streams 有一组函数式接口可以使用(实际上,函数式接口是使用 Streams 的唯一方式),但正如我之前提到的,它们的工作方式与 Collections API 略有不同。
为了使事情更清楚,请回顾以下示例:
fun main(args: Array<String>) {
val stream = 1.rangeTo(10).asSequence().asStream()
val resultantList = stream.filter{
it%2==0
}.collect(Collectors.toList())
println(resultantList)
}
前面的程序很简单;我们只是从 10 中抓取了一个数字流 1 并从该流中过滤掉奇数,然后将结果收集在里面一个新的 List。
但是,让我们尝试了解它的工作机制。我们已经 熟悉函数式接口和 filter 函数,正如我们在前几章中介绍的那样,但这里不同的是 collect 函数和 Collectors 值,这有助于将结果数据收集到一个新的 List。我们将在本章后面仔细研究 collect 方法和 Collectors 值,但现在,让我们查看 Streams 提供的功能接口和 Streams 的类型。
因此,以下是 Stream API 的操作/功能接口列表及其描述:
filter(): Works in the same way likeCollection.filterin Kotlin. It returns astreamvalues consisting of the elements of thisstreamthat match the given predicate.map(): Works in the same way asCollection.mapin Kotlin. It returns astreamvalue consisting of the results of applying the given function to each element of thisstream.mapToInt()/mapToLong()/mapToDouble(): Works the same way asmap, but instead of returning astreamvalue, they returnIntStream,LongStreamandIntStreamvalues, respectively. We are coveringIntStream,LongStream, andIntStreamin detail later in this chapter.
flatMap(): Works the same way asCollection.flatMapin Kotlin.flatMapToInt()/flatMapToLong()/flatMapToDouble(): Works the same way asflatMap, but instead of returning astreamvalue, they return theIntStream,LongStream, andIntStreamvalues, respectively.distinct(): Works in the same way asCollection.distinct. It returns astreamvalue of distinct elements.peek(): This function doesn't have any Kotlin Collection counterpart, however, it has a counterpart in RxKotlin/RxJava. This function returns thestreamvalue consisting of the elements of thisstream, additionally performing the provided action on each element, as elements are consumed from the resultingstream, much like thedoOnNextoperator of RxJava.anyMatch(): Similar toCollection.any(), it returns whether any elements of thisstreammatch the provided predicate. It may not evaluate the predicate on all elements, if not necessary for determining the result. If thestreamvalue is empty, then thefalsevalue is returned and the predicate is not evaluated.allMatch(): Similar toCollection.all, it returns whether all elements of thisstreammatch the provided predicate. It may not evaluate the predicate on all elements, if not necessary for determining the result. If thestreamvalue is empty, then thetruevalue is returned and the predicate is not evaluated.noneMatch(): Similar toCollection.none, it returns whether no elements of thisstreammatch the provided predicate. It may not evaluate the predicate on all elements, if not necessary for determining the result. If thestreamis empty, then thefalsevalue is returned and the predicate is not evaluated.
我们将跳过这些函数的示例,因为它们类似于 Collection 函数和 RxJava/RxKotlin 运算符。
那么,现在让我们看看 IntStream、DoubleStream 和 LongStream 我们之前提到的价值观,并探索它们的用途 。
原始流是在 Java 8 中引入的,以利用 primitive Java 中使用 Streams 时的数据类型(同样,Streams 基本上来自 Java,而 Kotlin 只是在 Streams API 中添加了一些扩展函数)。 IntStream、LongStream 和 DoubleStream 是这些 primitive 流。
这些原始流的工作方式与普通 Stream 类似,具有原始数据类型的一些附加功能。
所以,让我们举个例子;看看下面的程序:
fun main(args: Array<String>) {
val intStream = IntStream.range(1,10)
val result = intStream.sum()
println("The sum of elements is $result")
}
所以,我们用 IntStream.range() 函数创建了一个IntStream 值,range 函数将两个整数作为起点和终点,并创建一个范围为指定整数的 Stream,两者都包括在内。然后我们计算总和并打印出来。该程序看起来很简单,显然要归功于 IntStream,为什么?考虑一下轻松计算元素的总和;如果没有 IntStream,我们将不得不遍历所有元素来计算总和。
fun main(args: Array<String>) {
val doubleStream = DoubleStream.iterate(1.5,{item -> item*1.3})//(1)
val avg = doubleStream
.limit(10)//(2)
.peek {
println("Item $it")
}.average()//(3)
println("Average of 10 Items $avg")
}
在我们解释程序之前先看看下面的输出:
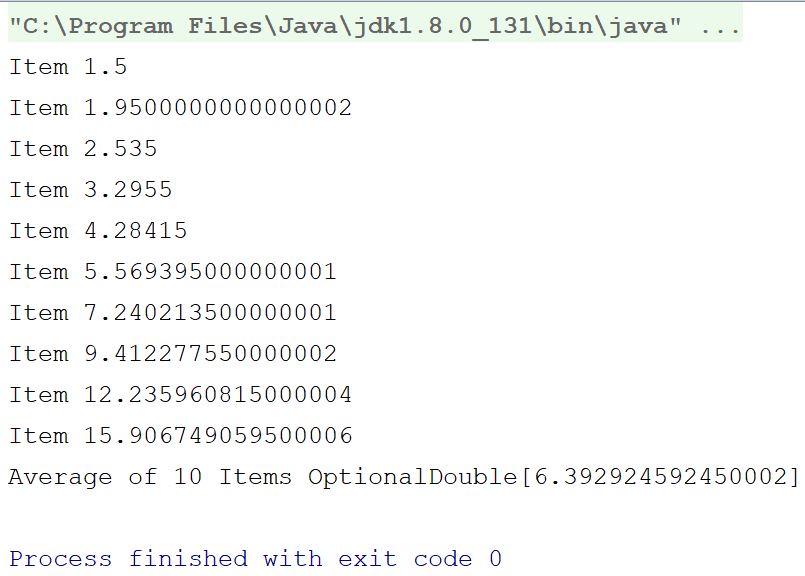
那么,让我们解释一下程序:
- On comment
(1), we created aDoubleStreamvalue with the factory methoditerate(). The iterate method takes adoubleas the seed of the Stream, and an operand, which will be iteratively applied to generate the elements of the Stream, for example if you pass x as the seed and f as the operator, the Stream will return x as the first element, f(x) as the second element, f(f(x)) as the third element, and so on. This function creates a Stream of infinite size. - We used the
limitoperator at comment(2), as we wanted only 10 elements from that stream, not all the elements till infinity. On comment(3), we calculatedaverage.
那么,让我们看看创建 Stream 的不同方法。
Streams API 提供了多种获取 Stream 实例的方法。以下是我们所涵盖的create 流的方法列表:
Stream BuilderStream.empty()Stream.of()Stream.generate()Stream.iterate()- Kotlin extension—
asStream()
在前面的列表中,我们已经看到了 Kotlin 扩展——asStream 和 Stream.iterate 函数的工作原理(它'将与前面示例中介绍的 DoubleStream.iterate value 的工作方式相同)。我们将看看其余的。
Stream Builder 界面使其真正易于创建< /span> 轻松实现 Stream 实例。看看下面的例子:
fun main(args: Array<String>) {
val stream = Stream.builder<String>()
.add("Item 1")
.add("Item 2")
.add("Item 3")
.add("Item 4")
.add("Item 5")
.add("Item 6")
.add("Item 7")
.add("Item 8")
.add("Item 9")
.add("Item 10")
.build()
println("The Stream is ${stream.collect(Collectors.toList())}")
}
输出如下:

Stream.builder() 方法返回 Streams.Builder 的实例。然后,我们使用了 Builder.add 函数; add 函数接受要构建的 stream 值的项目,并返回 Stream.Builder。 build 函数随后使用提供给构建器的项目创建了 stream 实例。
使用 Streams.empty() 创建 empty Streams 非常简单工厂方法。考虑 以下 示例:
fun main(args: Array<String>) {
val emptyStream = Stream.empty<String>()
val item = emptyStream.findAny()
println("Item is $item")
}
在前面的示例中,我们使用 Stream.empty() 创建了一个 emptyStream 值,然后我们使用了 findAny() 函数来获取从该 Stream 中随机选择的任何元素。 findAny() 方法返回一个 可选 值,其中包含从 Stream 中随机选择的项目,或一个空的 可选,如果流为空。
以下是上述程序的输出:

我们还可以通过将 elements 提供给 of 功能。 of 函数的工作方式类似于 RxJava/RxKotlin 中的 Observable.just 方法。
fun main(args: Array<String>) {
val stream = Stream.of("Item 1",2,"Item 3",4,5.0,"Item 6")
println("Items in Stream = ${stream.collect(Collectors.toList())}")
}
输出如下:

简单明了,不是吗?
我们也可以使用 Stream.generate()Stream > 工厂方法。它接受一个 lambda/supplier 实例作为参数,并在每次需要项目时使用它来生成项目。这个方法也创建了一个无限流。
考虑以下示例:
fun main(args: Array<String>) {
val stream = Stream.generate {
//return a random number
(1..20).random()
}
val resultantList = stream
.limit(10)
.collect(Collectors.toList())
println("resultantList = $resultantList")
}
输出如下:

因此,Stream API 调用 lambda 来获取 Stream 的每个元素——太棒了。
所以,既然我们已经非常熟悉如何使用 Streams 并且我们知道原始 Streams,让我们继续前进,看看如何使用 Collectors。
我们可以使用 Stream 执行许多 操作,但我们可能会遇到需要将 Stream 中的元素重新打包到一种数据结构。 Stream.collect() 方法可以帮助我们实现相同的目标。它是 Streams API 的终端方法之一。它允许您执行可变的fold操作(将元素重新打包到一些数据结构并应用一些额外的逻辑,将它们连接起来等等)在 Stream 实例中保存的数据元素上。
collect() 方法将 Collector 接口实现作为参数,用于策略(是否将它们重新打包为数据结构,连接它们,或其他任何东西)的收集。
那么,我们是否需要编写自己的 Collector 接口实现,以便将 Stream 重新打包成 List/设置 值?当然不是,Streams API 为一些最常见的用例提供了一些预定义的 Collector 实现。
Collectors 类包含预定义的 Collector 实现。所有这些都可以使用以下行导入:
import java.util.stream.Collectors
Collectors.toList()Collectors.toSet()Collectors.toMap()Collectors.toCollection()Collectors.joining()Collectors.groupingBy()
因此,让我们简要介绍一下它们中的每一个。
我们已经看到了 Collectors.toList() 的实现。 Collectors.toList() 方法有助于将 Stream 的元素收集到 List 中。 important 这里要注意的是你不能指定哪个List 实施使用;相反,它将始终使用默认值。
Collectors.toSet() 类似 到 Collectors.toList() 方法,只是代替 List, 它将元素重新打包成一个集合。同样,使用 Collectors.toSet(), 您将无法指定要使用的集合实现。
Collectors.toCollection() 方法是 toList() 和 toSet 的补充版本();它允许您提供一个自定义集合来累积列表。
考虑下面的例子来解释它:
fun main(args: Array<String>) {
val resultantSet = (0..10).asSequence().asStream()
.collect(Collectors.toCollection{LinkedHashSet<Int>()})
println("resultantSet $resultantSet")
}
输出如下:

Collectors.toMap() 函数帮助我们重新打包 将 Stream 放入 Map 实现。此功能提供了很多自定义。最简单的版本接受两个 lambda;第一个是确定 Map Entry的key,第二个lambda是确定 Map Entry的value。请注意,Stream 中的每个元素都将在 Map 中的一个条目中表示。
这两个 lambda 将在单独的迭代中获取 Stream 的每个元素,并预计会基于它们生成一个键/值。
看看下面的例子:
fun main(args: Array<String>) {
val resultantMap = (0..10).asSequence().asStream()
.collect(Collectors.toMap<Int,Int,Int>({
it
},{
it*it
}))
println("resultantMap = $resultantMap")
}
在这个程序中,我们使用了 Collectors.toMap() 函数的最简单版本。我们向它传递了两个 lambda,第一个确定条目的键将返回传递给它的相同值,另一方面,第二个计算并返回传递值的平方。这里要注意的重要一点是两个 lambda 将具有相同的参数。
输出如下所示:

Collectors.joining() 函数帮助你加入 Stream 的 elements ,包含字符串。它有三个可选参数,分别是——delimiter、prefix和postfix .
fun main(args: Array<String>) {
val resultantString = Stream.builder<String>()
.add("Item 1")
.add("Item 2")
.add("Item 3")
.add("Item 4")
.add("Item 5")
.add("Item 6")
.build()
.collect(Collectors.joining(" - ","Starts Here=>","<=Ends Here"))
println("resultantString $resultantString")
}
输出如下:

这个函数可以让我们将 Stream 的 elements 收集到 Map ; 对它们进行分组时起作用。此函数与 Collectors.toMap 的基本区别在于,此函数允许您创建一个 Map
Map 函数,该函数将保存一个
List value 作为每个组的值。
fun main(args: Array<String>) {
val resultantSet = (1..20).asSequence().asStream()
.collect(Collectors.groupingBy<Int,Int> { it%5 })
println("resultantSet $resultantSet")
}
输出如下:
