读书笔记《distributed-data-systems-with-azure-databricks》第9章深度学习的数据库运行时
Chapter 10: Model Tracking and Tuning in Azure Databricks
在上一章中,我们学习了如何创建机器学习和深度学习模型,以及如何在 Azure Databricks 中的分布式训练期间加载数据集。找到正确的机器学习算法来使用机器学习解决问题是一回事,但找到最佳超参数是另一个同样或更复杂的任务。在本章中,我们将重点关注使用 MLflow 作为模型存储库的模型调优、部署和控制。我们还将使用 Hyperopt 为我们的模型搜索最佳超参数集。我们将使用使用 scikit-learn Python 库制作的深度学习模型来实现这些库的使用。
更具体地说,我们将学习如何跟踪机器学习模型的训练运行以找到最佳超参数集,使用 MLflow 部署和管理模型的版本控制,并学习如何使用 Hyperopt 作为操作的替代方案之一,例如作为模型调整的随机和网格搜索。我们将涵盖以下主题:
- 使用 AutoML 调整超参数
- 使用 MLflow 自动跟踪模型
- 使用 Hyperopt 进行超参数调整
- 使用 scikit-learn、Hyperopt 和 MLflow 优化模型选择
在深入研究这些概念之前,让我们先了解一下本章的要求。
Tuning hyperparameters with AutoML
在机器学习和深度学习中,超参数调优是的过程,我们在这个过程中选择一组最佳超参数供我们的学习算法。在这里,超参数是用于控制学习过程的值。相反,将从数据中学习其他参数。从这个意义上说,超参数是一个遵循其统计意义的概念;也就是说,它是来自先验分布的参数,它在我们开始从数据中学习之前捕获先验信念。
在机器 学习和深度学习中,调用超参数也是我们开始训练模型之前设置的参数。 .这些参数将控制训练过程。深度学习中使用的超参数的一些示例如下:
- 学习率
- 时期数
- 隐藏层
- 隐藏单位
- 激活函数
这些参数将直接影响我们模型的性能和训练时间,它们的选择对我们模型的成功起着至关重要的作用。例如,学习率过低的神经网络将无法准确捕捉观察数据中的模式。找到好的超参数需要我们尽可能有效地映射搜索空间,这可能是一项艰巨的任务。这是因为要找到每组好的值,我们需要训练一个新模型,而这是一个在时间和计算资源方面可能很昂贵的操作。用于此的一些技术包括常见算法,例如网格搜索、随机搜索和贝叶斯优化。
AutoML 是我们可以用来更有效地搜索最佳超参数的技术之一,它 代表 自动机器学习。这是自动应用机器学习来解决优化问题的过程,在我们的例子中是优化我们训练算法中使用的超参数。这有助于我们克服手动搜索正确的超参数或应用网格和随机搜索等技术可能出现的问题,这些算法必须长时间运行。这是因为他们在搜索空间中搜索所有可能的值,而不评估这些区域的前景。
Azure Databricks Runtime for Machine Learning (Databricks Runtime ML) 为我们提供了两个选项来自动映射可能的超参数的搜索空间。它们被称为 MLflow 和 Hyperopt,这两个开源库应用 AutoML 来自动化模型选择和超参数调整。
HyperOpt 是一个 Python 库,专为模型超参数的大规模贝叶斯优化而设计。它可用于以分布式方式将搜索过程扩展到多个计算核心。虽然我们只关注超参数优化方面,但它也可以用于优化管道,以及数据预处理、学习算法选择,当然还有超参数调优。要使用 HyperOpt,我们需要定义一个优化器,该优化器将应用于所需的函数以优化任何函数,在我们的例子中可以最大化性能指标或最小化损失函数。在我们的示例中,HyperOpt 将采用超参数的搜索空间并根据先前的结果移动,从而以知情的方式在搜索空间中移动,使其与随机搜索和网格搜索等算法区分开来。
Azure Databricks Runtime for Machine Learning 中用于自动映射可能超参数的搜索空间的另一个可用库是 MLflow,我们在前面的章节中已经讨论过。 MLflow 是一个开源平台,用于管理端到端机器学习和深度学习模型生命周期,并支持自动模型调优跟踪。这种自动模型跟踪来自它与 Spark MLlib 库的集成。它允许我们使用 CrossValidator 和 TrainValidatorSplit 跟踪哪些超参数产生最佳结果,它们会自动将验证指标和超参数记录到更容易获得最佳模型。
在接下来的部分中,我们将学习如何应用 HyperOpt 和 MLflow 来跟踪获得已使用 Azure Databricks Runtime for Machine Learning 训练的模型的最佳超参数。
Automating model tracking with MLflow
正如我们之前提到的,MLflow 是一个用于管理机器和深度学习模型生命周期的开源平台,它使我们能够执行实验,确保可重复性,并支持简单的模型部署。它还为我们提供了一个集中的模型注册表。作为的总体概述,MLflow 的组件如下:
- MLflow Tracking:它 记录与实验相关的所有数据,例如代码、数据、配置和结果。
- MLflow 项目:它以一种格式包装代码,以确保结果可以在运行之间重现,而与平台无关。
- MLflow 模型:这 为我们的机器学习和深度学习模型提供了一个部署平台。
- 模型注册表:我们的机器学习和深度学习模型的中央 存储库。
在本节中,我们将重点介绍 MLflow Tracking,它是 组件,它允许我们记录和注册与深度训练相关的代码、属性、超参数、工件和其他组件学习和机器学习模型。 MLflow 跟踪组件依赖于两个概念,称为实验和运行。实验 是我们执行训练过程的地方,也是主要的组织单位;所有运行 都属于一个实验。因此,这些实验指的是特定的运行,我们可以对其进行可视化、比较并下载与之相关的日志和工件。以下信息存储在每个 MLflow 中:
- 来源:这是运行实验的笔记本。
- 版本:笔记本版本或 Git 提交哈希(如果运行是从 MLflow 项目触发的)。
- 开始和结束时间:训练过程的开始和结束时间。
- 参数:包含在训练过程中使用的模型参数 的字典。
- Metrics:包含模型评估指标的字典。 MLflow 记录并让您在整个运行过程中可视化模型的性能。
- 标签:这些 运行保存为键值对的元数据。您可以在运行完成期间和之后更新标签。键和值都是字符串。
- 工件:这些是运行中使用的任何格式的任何数据文件,例如模型本身、训练数据或任何其他类型的数据。
在用于机器学习的 Azure Databricks Runtime 中,每次我们在训练算法时在代码中使用 CrossValidator 或 TrainValidationSplit 时,MLflow 都会存储超参数和评估指标,以便更轻松地进行可视化并最终找到最佳模型。
在以下部分中,我们将学习如何在训练我们的算法时使用 CrossValidator 和 TrainValidationSplit,以利用 MLflow 的优势并可视化产生最佳结果的超参数。
Managing MLflow runs
当 我们在训练模型时使用 CrossValidator 或 TrainValidationSplit 时,我们将运行嵌套的 MLflow。这些将嵌套如下:
- 主运行:CrossValidator 或 TrainValidationSplit 的信息 记录到主运行。如果没有活动的运行,MLflow 将创建一个新的运行并登录到它,在退出进程之前结束它。
- 子运行:每个 超参数值及其相应的性能指标都记录在依赖于父运行的子运行中。
当我们为多步处理执行超参数搜索时,这些嵌套运行很常见。例如,我们可以有如下所示的嵌套运行:
这些嵌套运行将在 MLflow UI 中显示为可以展开的树,以便我们可以更详细地查看结果。这使我们能够将不同子运行的结果组织在主运行中。
当讨论 MLflow 运行管理时,我们需要确保我们正在登录到主运行。为确保这一点,当调用 fit() 函数时,应将其包装在 mlflow.start_run() 语句中以将信息记录到正确的运行中。正如我们已经看到的,通过这种方式,我们可以轻松地将指标和参数放入运行中。如果 fit() 函数在同一个活动运行中被多次调用,MLflow 会将唯一标识符附加到用于避免任何可能的冲突的参数和指标的名称命名。
在下一节中,我们将看到一个示例,说明如何将 MLflow 跟踪与 MLlib 结合使用,以找到机器学习模型的最佳超参数集。
Automating MLflow tracking with MLlib
在本节中,我们将举例说明使用 MLflow 来跟踪 PySpark MLlib DecisionTreeClassifier 模型的性能。 MLflow 将跟踪模型的学习,并允许我们存储过程中使用的所有工件。我们将把注意力集中在检查产生最佳结果的超参数上,以找到最佳设置。该模型将使用 MNIST 数据集进行训练,该数据集包含在 Databricks 示例数据集中。数据集采用 LIBVSM 格式,分为训练数据和测试数据。它包含两列——一列用于标签,另一列用于以 784 个特征编码的图像。让我们开始吧:
- 首先,我们将在指定特征数量的同时加载数据,并将数据缓存在工作内存中:
- After this, we can display the number of records in each dataset and display the training data:
要将这些特征传递给机器学习模型,我们需要做一些特征工程。我们可以使用 MLlib 将这些操作标准化为单个管道,这允许我们将多个预处理操作打包到单个 工作流中。 MLib Pipelines 与 scikit-learn 中的管道实现非常相似,有五个主要组件。这些如下:
- DataFrame: The actual DataFrame that holds our data.
- Transformer: The algorithm that will transform the data in a features DataFrame into data for a predictions DataFrame, for example.
- Estimator: This is the algorithm that fits on the data to produce a model.
- Parameter: The multiple
TransformerandEstimatorsparameters specified together. - Pipeline: The multiple Transformer and Estimators operations combined into a single workflow.
在这里,我们将有一个由两个步骤组成的管道,一个是 StringIndexer,用于将标签从数字特征转换为分类特征,另一个是 DecisionTreeClassifier< /code> 模型,它将根据特征列中的训练数据预测标签。让我们开始吧:
- 首先,让我们进行必要的导入并创建管道:
- 现在,我们 可以实例化StringIndexer 和DecissionTreeClassifier:
- 最后,我们可以将 StringIndexer 和 DecissionTreeClassifier 链接到一个工作流中:
- So far, we have followed the standard way of creating a normal pipeline. What we will do now is include the CrossValidator MLflow class so that we can run the cross-validation process of the model. The evaluation metrics of each validated model will be tracked by MLflow and will allow us to investigate which hyperparameters yielded the best results.
在本例中,我们将在 CrossValidator MLflow 类中指定两个要检查的超参数,如下所示:
a)
maxDepth:该参数决定了树在DecissionTreeClassifier中可以生长的最大深度。更深的树可以产生更好的结果,但训练成本更高,并且返回倾向于过度拟合的模型。b)
maxBins:此参数确定将生成的 bin 数,以将连续特征离散化为有限的数字集。它是在分布式计算环境中进行训练时以更有效的方式训练模型的参数。在此示例中,我们将首先指定值 2,这会将灰度特征转换为 1 或 0。我们还将使用 4 的值进行测试,以便我们有更大的粒度。 - 现在,我们 可以定义我们将用来衡量模型性能的评估器。我们将使用 PySpark
MulticlassClassificationEvaluator然后使用weightedPrecision作为度量: - 接下来,我们将定义要检查的参数网格:
- 现在,我们已经准备好使用之前定义的管道、评估器和超参数网格来创建 CrossValidator。正如我们之前提到的,CrossValidator 将跟踪我们创建的模型,以及我们使用的超参数:
- 一旦我们定义了交叉验证过程,我们就可以开始训练过程。如果 MLflow 跟踪服务器可用,它将开始记录我们每次运行的数据,以及在 当前活动运行下运行中使用的所有其他工件.如果我们没有一个活跃的运行,它将创建一个新的:
- 在前面的代码中,我们创建了一个新的运行来跟踪模型。请记住,我们使用
和 mlflow.start_run(): 语句来避免在多次运行单元时遇到任何命名冲突。前面的步骤将保证cv.fit()函数返回它能够找到的最佳模型,然后我们在测试数据上评估它的性能,然后记录MLflow 中的评估结果:
图 10.1 - 使用 MLflow 跟踪训练运行
- 一旦我们完成了训练过程,我们将能够在 Azure Databricks Workspace 的 下的 MLflow UI 上看到结果模型 标签。我们还可以通过单击我们正在训练模型的笔记本中的 experiment 图标来查看训练过程的结果。我们可以通过点击 Experiment Runs 轻松比较不同运行的结果,这将允许我们查看所有笔记本运行:
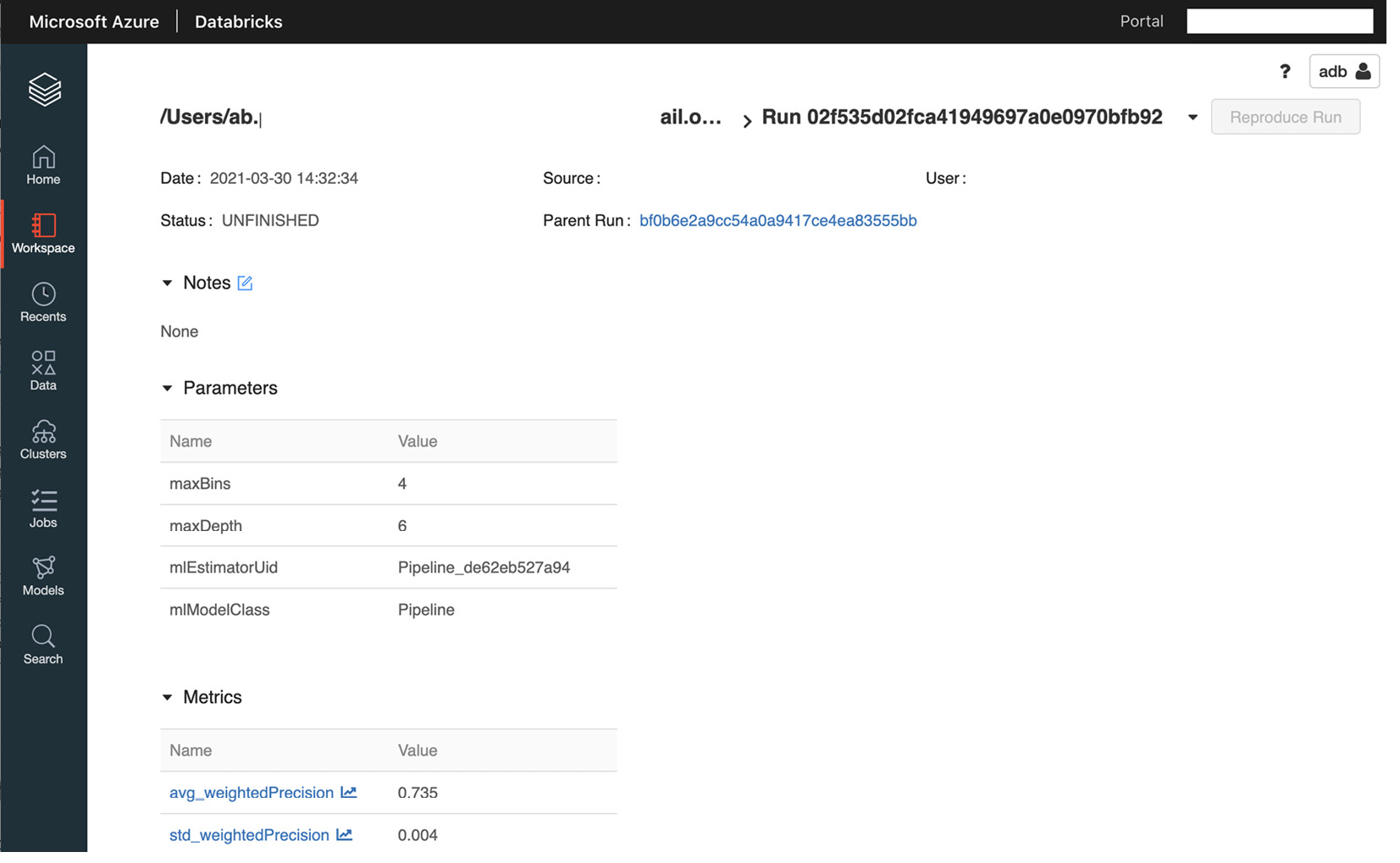
图 10.2 – MLflow 模型注册表 UI
我们可以通过在搜索运行框中传递一个参数来显式查找这些运行的具体结果。例如,我们可以通过传递 maxDepth 超参数中使用 6 的值时得到的结果="literal">params.maxDepth = 6 在搜索框中。
我们还可以通过创建用于特定性能指标的超参数的不同值的散点图来比较结果,这在我们尝试查找和比较最佳超参数集。
下一节将深入探讨一种更自动的方法,以找到最小化某个函数的最佳超参数集。我们将使用损失函数来做到这一点。我们将使用 Hyperopt 来定义和探索搜索空间,并找到最小化损失函数的超参数。
Hyperparameter tuning with Hyperopt
Azure Databricks Runtime for Machine Learning 包括 Hyperopt,这是一个 Python 库,旨在用于分布式计算系统,以促进一组最优超参数的学习过程。它的核心是一个库,它接收我们需要最小化或最大化的函数,以及一组定义搜索空间的参数。有了这些信息,Hyperopt 将探索搜索空间以找到最佳的超参数集。 Hyperopt 使用随机搜索算法来探索搜索空间,这比使用传统的确定性方法(如随机搜索或网格搜索)要高效得多。
Hyperopt 针对在分布式计算环境中的使用进行了优化,并提供了对诸如 PySpark MLlib 和 Horovord 等库的支持,后者是用于分布式深度学习的库 我们稍后将重点介绍的培训。它也可以应用于单机环境以及其他更常见的库,例如 TensorFlow 和 PyTorch。
使用 Hyperopt 时的一般工作流程如下:
- 首先,我们必须找到我们想要优化的功能。这可以是我们想要最大化的性能指标,也可以是我们想要最小化的损失函数。
- 接下来,我们必须定义条件搜索空间,Hyperopt 将在其中扫描最佳参数以优化定义的目标函数。 Hyperopt 支持在同一运行中使用多种算法,这允许我们定义多个模型进行探索。
- 之后,我们必须定义将用于扫描搜索空间的搜索算法。
- 最后,我们可以通过运行
fmin()Hyperopt 函数来开始探索过程。这将把目标函数作为参数和用于识别最优参数集的搜索空间。
- 我们将作为优化目标传递的目标函数。通常,这是一个损失函数或性能指标。
- 定义搜索空间的超参数字典。我们可以为每组超参数值选择不同的分布。
在下一部分中,我们将学习如何将 Hyperopt 应用到 Azure Databricks Runtime for Machine Learning,以找到特定任务的最佳超参数,而不管应用的算法如何。
Hyperopt concepts
在本节中,我们将通过 Hyperopt 的某些概念来确定其核心功能,以及我们如何使用它们来有效地扫描搜索空间以查找有助于最小化或最大化我们的目标函数。正如我们之前提到的,当我们开始使用 Hyperopt 时,我们必须定义以下内容:
- 目标函数
- 我们将扫描的搜索空间
- 将用于保存在搜索空间中评估点的结果的数据库
- 将用于扫描搜索空间的搜索算法
在这里,我们的主要目标是找到代表最佳超参数的最佳标量集。 Hyperopt 允许我们详细定义搜索空间,以提供有关目标函数在搜索空间中的哪个位置执行得更好的信息。其他优化库通常假设搜索空间是具有相同分布的较大向量空间的子集,但通常情况并非如此。 Hyperopt 让我们定义搜索空间的方式使我们能够执行更有效的扫描。
Hyperopt 允许我们非常简单地定义目标函数,但是当我们增加参数数量时,它也会增加复杂性,我们希望在执行过程中跟踪。最简单的例子如下,我们找到x的值,它使一个线性函数最小化,y(x) = x :
- Hyperopt
fmin()函数接受fn关键字参数和要最小化的函数。在这种情况下,我们使用了一个非常简单的 lambda 函数;也就是说,f(y)=x。 - space 参数用于传递搜索空间。在这里,我们使用 Hyperopt 的
hp函数为x变量指定一个统一的搜索空间,范围为 0 到1.hp.uniform是一个内置在库中的函数,可帮助我们指定特定变量的搜索空间。 algo参数用于选择搜索算法。在这种情况下,tpe代表 Parzen 估计器。我们可以也将这些参数设置为hyperopt.random.suggest。搜索算法是一个完整的主题,因此我们将仅简要提及这一点,但您可以自由搜索有关 Hyperopt 应用的算法类型的更多详细信息,以找到最适合您的超参数集。- 最后,使用
max_evals参数指定最大评估次数。
一旦我们指定了所有必需的参数,我们就可以开始运行,它将返回一个 Python 字典,其中包含最小化目标函数的指定变量的值。
尽管我们这里的最小工作示例看起来非常简单,但 Hyperopt 的复杂性随着我们在优化目标函数时所拥有的规范数量而增加。当我们提出最佳策略时,我们可以问自己的一些问题如下:
- 除了
fmin()函数的实际返回值,还需要什么类型的信息?我们可以获得在此过程中收集的统计数据和其他数据,这些数据可能对我们有用。 - 我们是否有必要使用需要多个输入值的优化算法?
- 我们是否应该并行化这个过程,如果是,我们是否希望这些并行过程之间进行通信?
回答这些问题将定义我们实施优化策略的方式。
在并行优化过程中,Hyperopt优化算法与目标函数之间发生通信,以获得目标函数在搜索空间特定点的实际值。在这种通信中,在该浮点损失中返回目标函数的值(也称为负效用)与搜索空间中的该点相关联。
此处显示的简单示例说明了使用 Hyperopt 定义目标函数和搜索空间是多么简单。但是,在我们想要存储更多信息而不仅仅是搜索空间中目标函数返回的浮点值的情况下,它仍然存在不足。它也是一种不与搜索算法或并发函数交互的评估。
为了解决第一个问题,我们可以使用一个目标函数,该函数通过返回一个嵌套字典来检索多个值,其中包含所需的统计和诊断的键值。为此,我们有一组强制值,我们的目标函数必须返回:
status:我们可以从hyperopt.STATUS_STRINGS中选择一个key来显示比赛的状态。这样,我们可以跟踪我们的评估是成功完成还是失败。loss:这是实际目标函数在搜索空间中的特定点进行评估时返回的浮点值。如果比赛状态良好,则必须存在。
我们还可以在目标函数的选项中指定 一些额外的可选参数。这些关键值如下:
loss_variance:一个浮点值,指定随机目标函数的确定性。true_loss:可以用这个名字存储模型的loss,这样我们就可以使用内置的绘图工具了。这在我们使用超参数优化时特别有用,因为它允许我们非常简单地绘制探索结果。true_loss_variance:模型损失的不确定性。
此功能允许我们将这些值存储在与 JSON 兼容的数据库中,例如 MongoDB。下面的代码示例向我们展示了如何定义一个非常简单的 f(x) = x 目标函数,它将执行状态作为键值字典返回:
我们可以通过使用 Trials 对象充分利用能够返回字典的优势,这允许我们在执行优化时存储更多信息。在以下示例中,我们正在修改目标函数以返回更复杂的输出,该输出稍后将存储在 Trials 对象中。我们可以通过将其 作为 Hyperopt fmin() 函数的参数传递来做到这一点:
执行完成后,我们可以访问 Trials 对象来检查目标函数在优化期间返回的值。我们有不同的方式可以访问存储在 Trials 对象中的值:
trials.trials:返回包含所有搜索参数的字典列表。trials.results:目标函数返回的字典。trials.losses():所有成功试验的实际损失。trials.statuses():每个试验的状态。
这个Trials对象可以保存为pickle对象或者使用自定义代码解析,让我们对结果有更深入的了解审判。
可以像这样访问试验的附件:
在此示例中,我们正在获取第一次试用的 time_module 附件。
需要注意的重要一点是,在 Azure Databricks 中,我们可以选择将 Trials 和 SparkTrials 对象传递给fmin() 函数的试验参数。当我们执行单机算法(例如 scikit-learn 模型)作为目标函数时,会传递 SparkTrials 对象。在这里,Trials 对象用于分布式训练算法,例如 MLlib 或 Horovod 模型。 SparkTrials 类允许我们分发优化的执行,而无需引入任何自定义逻辑。它还改进了计算分配给工作人员。
不要将 SparkTrials 对象与为分布式训练设计的算法一起使用,因为这将导致在集群中并行执行。
现在我们对如何配置 fmin() Hyperopt 函数的基本参数有了更清晰的了解,我们可以深入了解如何定义搜索空间。
Defining a search space
我们可以将 搜索空间表示为一组嵌套函数,这些函数 为不同的测试用例定义了单独的搜索空间。例如,在下面的代码块中,我们为 x 参数指定搜索空间,其中包含两个名为 test_space_1 的测试空间和test_space_2:
在这里,Hyperopt 将根据搜索算法从这些嵌套的随机表达式中进行采样。该算法采用自适应探索策略,而不仅仅是从搜索空间中抽取样本。在前面的示例中,我们定义了三个参数:
a:选择要使用的大小写test_space_1:为x参数生成正值test_space_2:为y参数生成正值
每个表达式都有标签作为第一个参数,算法在内部使用该标签将参数选择返回给调用者。在此示例中,代码的工作方式如下:
- 如果
a变量为 0,我们将使用x而不是y. - 如果
a变量为 1,则将使用y但不使用x。
x 和 y 变量是条件参数,取决于 a 的值的结果
。如果我们以这种条件方式对变量进行编码,则说明 x 变量在 a 时对目标函数没有影响为 0,这有助于搜索算法以更有效的方式分配信用。这利用了用户对要分析的目标函数的领域知识。
search_space 是一个变量空间,它被定义为一个图形表达式,描述了如何在不生成搜索空间的情况下对一个点进行采样。这优化了执行的内存和计算使用。这些图表达式称为 pyll 图,并在 hyperopt.pyll > 类。
您可以通过采样来探索示例搜索空间:
我们现在知道如何定义优化目标函数的搜索空间。重要的是要注意,我们定义要在搜索空间中测试的案例的方式也会影响搜索算法在自适应搜索期间对试验的工作方式。在下一部分中,我们将了解在 Azure Databricks 中使用 Hyperopt 的一些最佳做法。
Applying best practices in Hyperopt
到目前为止,我们已经讨论了如何指定要最小化的目标函数的执行以及我们将在其中评估它的搜索空间。此外,我们已经看到有在我们如何定义探索超参数的可能值的方式以及如何通过在搜索空间中定义条件参数来利用领域知识方面具有很大的灵活性。
我们必须牢记 Hyperopt 库本身的某些方面,以及它在 Azure Databricks 中的执行方式。以下是在 Azure Databricks 中使用 Hyperopt 优化目标函数时需要记住的一些重要概念:
- Partzen Estimator 算法的 Hyperopt 树是一种贝叶斯方法,比常见的网格和随机搜索方法更有效。它允许我们扫描更大的一组可能的超参数。在定义搜索空间时应用领域知识以提高探索的性能。
- 当我们使用
hyperopt.choice()和 MLflow 跟踪优化的进度时,MLflow 会记录选择列表的索引。我们可以使用 Hyperopthyperopt.space_eval()函数获取参数值。 - 在处理大型数据集时,始终建议对数据的小子集进行试验,以逐步了解最佳搜索空间。这有助于我们定义将在整个数据集上使用的那个。
- 当我们使用 SparkTrials 对象时,建议使用纯 CPU 集群。这是因为在 Azure Databricks 中,与 CPU 集群相比,GPU 集群中的并行度有所降低。
- 不要在自动缩放集群上使用 SparkTrials,因为在执行开始时选择了并行度值。因此,如果集群扩展,它不会提高执行性能。
应用这些概念将确保我们利用 Azure Databricks 中的 Hyperopt 优化执行。在下一节中,我们将详细了解如何在 Azure Databricks 中改进深度学习模型的推理。
Optimizing model selection with scikit-learn, Hyperopt, and MLflow
正如我们在前面的章节中看到的 ,Hyperopt 是一个 Python 库,它允许我们跟踪优化 可用于超参数模型调优分布式计算环境< /a> 例如 Azure Databricks。在本节中,我们将通过一个训练 scikit-learn 模型的示例。我们将使用 Hyperopt 跟踪调优过程并将结果记录到模型生命周期管理平台 MLflow。
在用于机器学习的 Azure Databricks Runtime 中,我们可以使用 Hyperopt 的优化版本,它支持 MLflow 跟踪。在这里,我们可以使用 SparkTrials 对象来记录并行执行期间单机模型的调优过程的结果。我们将使用这些工具为几个 scikit-learn 模型找到最佳的超参数集。
我们将执行以下操作:
- 准备训练数据集。
- 使用 Hyperopt 定义要最小化的目标函数。
- 定义一个 Hyperopt 搜索空间,我们将在其上扫描最佳超参数。
- 定义将用于扫描搜索空间的搜索算法。
- 执行优化并跟踪 MLflow 中的最佳参数集。
让我们开始吧:
- 首先,我们将导入所有必要的库,我们将正在使用:
- 在此示例中,我们将使用加利福尼亚住房数据集,该数据集作为示例数据集包含在 scikit-learn 中。该数据集包含来自 1990 年美国人口普查的数据,其中包含加利福尼亚州 20,000 所房屋的房屋价值,以及一些包含有关收入、居民数量、房间等数据的特征。为了获取这个数据集,我们将使用
fetch_california_housing()scikit-learn 函数并将结果转储到名为 features 和 target 的变量中: - Now that we have split our dataset into the features and the target, we will scale the prediction variables, which is a common practice in machine learning and deep learning. This way, we will ensure we have scaling consistency. This will help us overcome several problems that arise when our features have not been discretized into scaled variables. The features that are available in our dataset are as follows:
a) 每块房屋收入中位数
b) 房屋年龄
c) 每栋房屋的平均房间数
d) 平均卧室数量
e) 总区块人口
f) 平均住户人数
g) 纬度
h) 经度
- 通过查看每列中特征的规模——可以使用
describe()方法在 pandas DataFrame 中完成的简单操作——我们可以看到数量级在平均值变化很大: - 正如我们所看到的,这些变量的范围和尺度可能非常不同:

图 10.3 – 特征统计总结
- 一个区块的人口以千为单位,但的平均数量>卧室以 1.1 为中心。为了防止 值较大的特征被认为更重要的情况,缩放特征并对其进行标准化是一种标准做法.为了标准化特征以使它们具有相同的比例,我们可以使用 scikit-learn
StandardScaler函数: - 现在我们已经缩放了预测特征,我们可以通过调用
mean(axis=0)NumPy 方法来检查均值是否接近于scaled_features数据集: - 现在我们的预测特征已经被标准化和缩放,我们必须将数字目标列转换为离散值:

图1.4 –缩放特征0意义
- 这个目标列向量是每个房子的值,是一个连续正标量。我们将把它转换成一个目标列向量,其中当离散值为1 a>房屋价值大于均值,否则为0。这样,可以将预测框定为一个问题;例如,给定预测特征,这所房子的值是否大于平均值?为了离散化这些值,我们将其与平均值进行比较,并使用
numpy.where()函数将比较产生的布尔值转换为 1 和 0:我们将各个编码为具有等级(或0)的列。这表明两个指标是否均等值。
- 现在我们已经准备好了数据集,我们可以开始为优化几个 scikit-learn 模型的超参数做好准备,我们将使用这些模型来训练有效的分类模型。为此,我们将使用以下三个 scikit-learn 分类器模型:
b) 逻辑回归森林
c) 随时
- 我们将创建一个要最小化的目标函数,并将其传递给Hyperopt。这将运行训练并计算定义为“类型”参数的几种模型类型的交叉验证性能指标。 关于这个 函数需要注意的一件事是,因为我们使用的是
fmin()Hyperopt 函数,这个 将尝试最小化目标函数。因此,为了提高性能指标——在这种情况下是准确度——我们必须使用负准确度。否则,Hyperopt 会尽量降低准确率,这是我们显然不想做的事情:请注意,这个函数的输出是有两个必须参数的键值字典。是“损失”(负使用我们)和“状态”(在导入之前的 Hyperopt 状态字符串之一定义)。
- The next step is to define the search space we will use to scan all the possible hyperparameters for each of the selected scikit-learn models. This will help us find the one that yields the best accuracy. We will use the
hyperopt.choice()function to select the different models and specify the search space for each classification algorithm. The label of this selection isclassifier_type. It will iterate over the previously defined types of algorithms in the objective function based on the given labels in the search space:搜索空间表达式内的
hyperopt.choice()函数将传递'type'参数 到目标函数,该函数又创建一个名为内部变量"literal">classifier_type并使用 它来选择 适当的算法。然后它将剩余的参数传递给模型。请注意,在目标函数中,'type'参数是如何在创建内部变量后被删除的,以避免目标算法中任何可能的命名冲突。 - Now, we must choose the search algorithm that will be used to scan the search space. As we have seen previously, Hyperopt provides us with two main options for this:
a)
hyperopt.tpe.suggest:这是 Parzen 估计器树 (TPE) 算法,这是一种贝叶斯算法,根据之前的结果自适应地选择超参数。b)
hyperopt.rand.suggest:这是一种随机搜索算法,与 TPE 算法的不同之处在于它是一个 non -在搜索空间上使用采样策略的自适应方法。 - 在本例中,我们将使用 TPE 算法,因此我们将选择
tpe.suggest,如下所示: - The next step is to define the object that will hold the results of each of the trials. We will use SparkTrials to keep track of the progress of the exploration and log it in MLflow. As we mentioned previously, we will use the SparkTrials object instead of the native
TrialsHyperopt object because we are using algorithms designed to be run on a single machine. If we were to use an MLlib algorithm, we must use the MLflow API to keep track of theTrialsresult.反过来,SparkTrials 是 一个可以接收两个 可选参数的对象,如 如下:
a)
parallelism:这是并行拟合和评估的算法数量。此参数的默认值等于可用的 Spark 任务槽数。b)
timeout:fmin()可以运行的最长时间(以秒为单位)。没有最长时间限制。Spark 中默认的
parallelism值为8。建议的设置是将此值显式设置为正值,因为 Spark 任务槽取决于集群的大小。 - 准备优化运行的最后一步是使用
mlflow.start_run()MLflow 包装器。我们将使用它在 MLflow 平台中记录此探索的结果。这将自动跟踪运行的进度,以及目标函数中所有定义的 变量和标签并进行搜索空间: max_evals参数 允许我们指定 中的最大点数将被评估的搜索空间。因此,我们可以将此值视为 Hyperopt 将为每个搜索空间拟合和评估的最大模型数:
图 10.5 - 使用 MLflow 跟踪训练运行
- Once the execution has been finalized, we can examine the hyperparameters that produced the best result:
我们应该看到 最佳超参数集 在控制台中打印为“键值字典”以及名称和在定义的最小化函数的搜索空间中找到的最佳参数值:

图 10.6 – 最佳超参数
我们可以点击experiment图标查看MLflow实验笔记本的右上角。此 选项将显示在运行和,正如我们之前提到的,允许我们可视化产生最佳结果的一组超参数和算法。我们还可以检查改变特定参数的效果。
通过这种方式,我们可以同时调整多个模型,并跟踪模型在每个定义的搜索空间中的性能。借助 Hyperopt 和 MLflow,我们可以轻松定义高级管道,以使用 Azure Databricks Runtime for Machine Learning 并行微调模型。
Summary
在本章中,我们了解了 Azure Databricks 的一些有价值的功能,这些功能使我们能够使用 MLflow 模型注册表跟踪训练运行,以及找到机器学习模型的最佳超参数集。我们还学习了如何优化使用 Hyperopt 扫描最优参数的搜索空间。这是一组很棒的工具,因为我们可以微调对用于训练的超参数具有完整跟踪的模型。我们还使用自适应搜索策略探索了定义的超参数搜索空间,该策略比常见的网格和随机搜索策略优化得多。
在下一章中,我们将探讨如何使用集成到 Azure Databricks 中的 MLflow 模型注册表。 MLflow 可以更轻松地跟踪机器学习模型的整个生命周期以及训练过程中使用的所有相关参数和工件,但它也允许我们轻松部署这些模型,以便我们可以发出 REST API 请求以获取预测。 Azure Databricks 中的这种 MLflow 集成增强了创建和部署机器学习模型的整个工作流程。