JDK17 |java17学习 第 15 章反应式编程
Technical requirements
为了能够执行本章提供的代码示例,您将需要以下内容:
- 装有 Microsoft Windows、Apple macOS 或 Linux 操作系统的计算机
- Java SE 版本 17 或更高版本
- 您喜欢的 IDE 或代码编辑器
第 1 章,Java 17 入门。本章的代码示例文件可在 GitHub 上的 https:// examples/src/main/java/com/packt/learnjava/ch16_microbenchmark 文件夹中的 github.com/PacktPublishing/Learn-Java-17-Programming.git 存储库.
What is JMH?
根据牛津英语词典, 基准 是 一个标准或点可以比较或评估事物的参考依据。在编程中, 它是比较应用程序或方法的 性能 的方法。 微前言 关注后者——更小的代码片段,而不是整个应用程序。 JMH 是一个用于衡量单一方法的 性能的框架。
这可能看起来非常有用。我们能否不只是在循环中运行一个方法 1,000 或 100,000 次,测量它所用的时间,然后计算该方法的平均性能?我们可以。问题在于 JVM 是一个比代码执行机器复杂得多的程序。它具有专注于使应用程序代码尽可能快地运行的优化算法。
例如,让我们看看下面的类:
我们 用没有多大意义的代码填充了 someMethod() 但让方法保持忙碌。为了测试此方法的性能,很容易将代码复制到一个测试 方法中并循环运行:
但是,JVM 会看到 res 结果 从未 使用过, 将计算限定为 死代码
(从未执行过的代码 部分)。那么,为什么还要费心执行这段代码呢?
您可能 惊讶地发现 算法的显着 复杂性或简化 不影响 性能。这是因为,在任何情况下, 代码实际上并没有 执行。
这可能会说服 JVM 每次都执行代码,但这并不能保证。 JVM 可能会注意到 输入到计算中的 没有改变,并且这个算法 每次运行都会产生相同的结果。由于代码基于常量输入,因此这种优化 被称为 常量折叠。这种优化的结果是这段代码可能只执行一次,并且每次运行都假定相同的结果,而不实际执行代码。
但在实践中,基准测试通常是围绕一种方法构建的,而不是代码块。例如,测试代码可能如下所示:
但即使是这段代码也容易受到我们刚刚描述的相同 JVM 优化 的影响。
创建 JMH 是为了帮助避免这种和类似的陷阱。在 JMH 使用示例 部分,我们将向您展示如何使用 JMH 解决死代码和常量折叠优化, 使用 @State 注解和 Blackhole 对象。
此外,JMH 不仅可以测量平均执行时间,还可以测量吞吐量和其他性能特征。
Creating a JMH benchmark
要开始使用 JMH,必须将以下 依赖项 添加到 pom.xml 文件中:
第二个 .jar 文件的名称, annprocess,提供了 JMH 使用注释的提示。如果你猜对了,那就对了。以下是为测试算法性能而创建的基准测试示例:
请注意 @Benchmark 注解。 它告诉 框架 这个方法的性能必须被测量。如果你运行前面的 main() 方法,你会看到类似下面的输出:
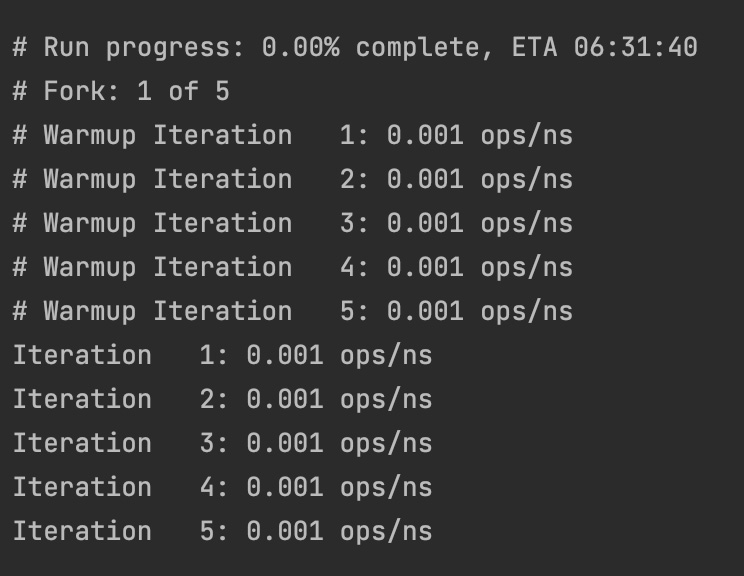
这只是广泛输出的一部分,包括不同条件下的多次迭代,目的是避免或抵消JVM优化。它还考虑了运行代码一次和多次运行之间的区别。在后一种情况下,JVM 开始使用即时编译器,它将常用字节码的代码编译成本机二进制代码,甚至不读取字节码。 热身 循环服务于这个目的——代码在执行时没有测量其性能作为 热身 JVM的干运行。
还有一些方法可以告诉 JVM 直接编译和使用哪种方法作为二进制文件,每次编译哪种方法,并提供类似的指令来禁用某些优化。我们将很快讨论这个问题。
现在让我们看看如何运行基准测试。
Running the benchmark
正如您可能已经猜到的,运行基准测试的一种方法 就是执行 main() 方法.可以直接使用 java 命令或使用IDE来完成。我们在 第 1 章< /a>, Java 17 入门。然而,有一种更简单、更方便的方法来运行基准测试:使用 IDE 插件。
Using an IDE plugin
所有主要的 Java-支持 IDE 都有这样的插件。我们将 演示 如何使用安装在 macOS 计算机上的 IntelliJ 插件,但它同样适用于 Windows 系统。
以下是要遵循的步骤:
- 要开始安装插件,请同时按下 命令 键和 逗号 (,) 单击顶部水平菜单中的扳手符号(带有悬停文本 首选项):
- 它将在左窗格中打开一个带有以下菜单的窗口:

- 选择 Marketplace,输入
JMH在 Marketplace中的搜索插件 strong> 输入字段,然后按 Enter。如果您有互联网连接,它将显示一个 JMH 插件 符号,类似于以下屏幕截图中显示的符号:
- IDE 重启后,插件就可以使用了。现在,您不仅可以运行
main()方法 还可以选择 如果你有几个 方法要执行的基准方法@Benchmark注解。为此,请从 运行 下拉菜单中选择 运行...
- 选择您要运行的那个,它将被执行。至少运行一次方法后,只需右键单击它并从弹出菜单中执行它:
- 您还可以使用每个菜单项右侧显示的快捷方式。
JMH benchmark parameters
有许多基准参数,可以根据手头任务的特定需求对测量结果进行微调。我们将只介绍主要的。
Mode
Mode.AverageTime:测量平均执行时间Mode.Throughput:通过在迭代中调用基准方法来测量吞吐量Mode.SampleTime:对执行时间进行采样,而不是对其进行平均; 允许我们推断分布、百分位数等Mode.SingleShotTime:测量单个方法 调用 时间; 允许在不连续调用基准方法的情况下进行冷启动测试
这些参数可以在注解中指定 @BenchmarkMode,例如:
可以组合几种模式:
也可以请求所有这些:
所描述的参数 以及我们将在本章后面讨论的所有参数都可以在方法和/或类级别设置。方法级别的设置值会覆盖类级别的值。
Output time unit
用于呈现结果的时间单位可以 指定 使用 @OutputTimeUnit 注解:
可能的时间单位来自 java.util.concurrent.TimeUnit 枚举。
Iterations
Forking
在运行 多个测试时, @Fork annotation 允许您将每个测试设置为在单独的进程中运行, 例如:
传入的参数值表示 JVM 可以 分叉 成独立进程的次数。默认值为 -1。 没有它,如果您在测试中使用多个实现相同接口的类,测试的性能可能会混合 它们会相互影响。
warmups 参数是 另一个可以设置 指示基准必须执行多少次而不收集测量值的参数:
它还允许您将 Java 选项添加到 java 命令行,例如:
JMH 参数的完整列表以及如何使用它们的示例可以在 openjdk project (http://hg.openjdk.java.net/code -tools/jmh/file/tip/jmh-samples/src/main/java/org/openjdk/jmh/samples)。比如我们没有提到 @Group, @GroupThreads, @Measurement, @Setup, @Threads, @Timeout、 @TearDown 或 @Warmup。
JMH usage examples
现在让我们运行 几个测试并比较它们。首先,我们运行 以下测试方法:
如您所见,我们要求测量所有性能特征并在呈现结果时使用纳秒。在我们的系统上,测试执行大约需要 20 分钟 ,最终结果摘要如下所示:
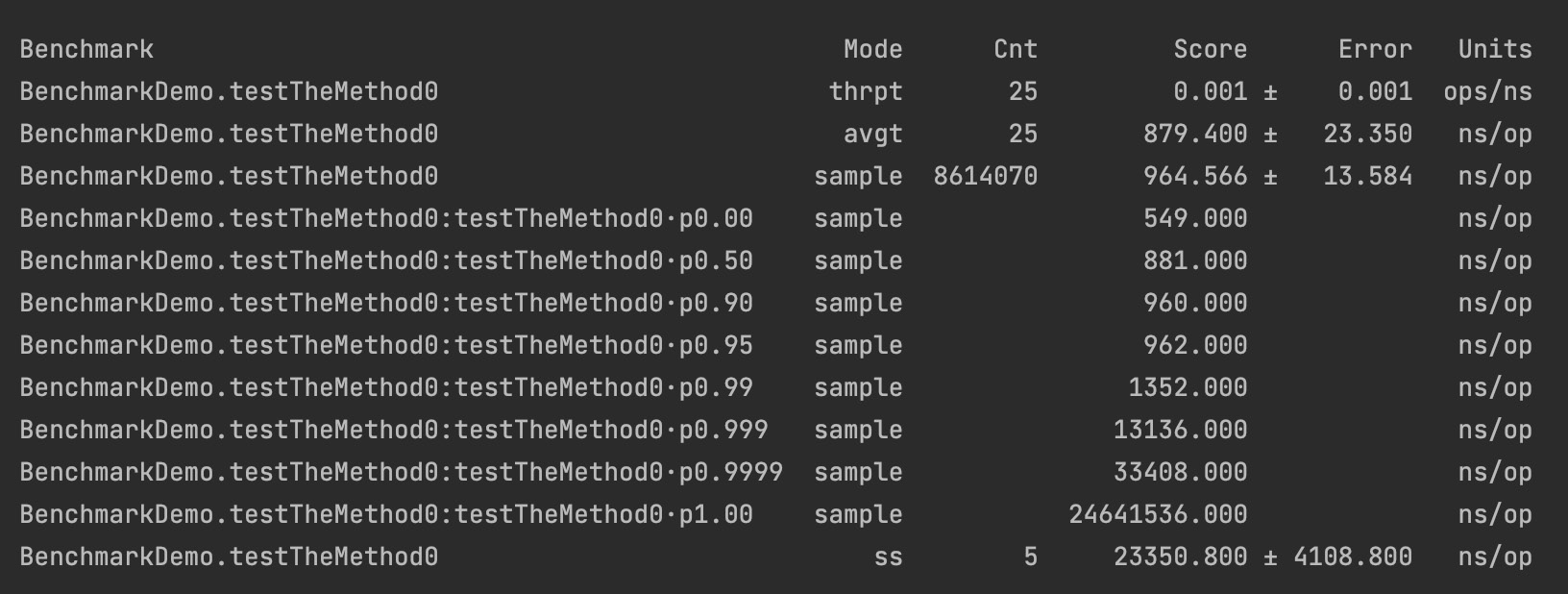
现在让我们将测试更改如下:
如果我们现在运行 testTheMethod1() ,结果 会 略有不同:
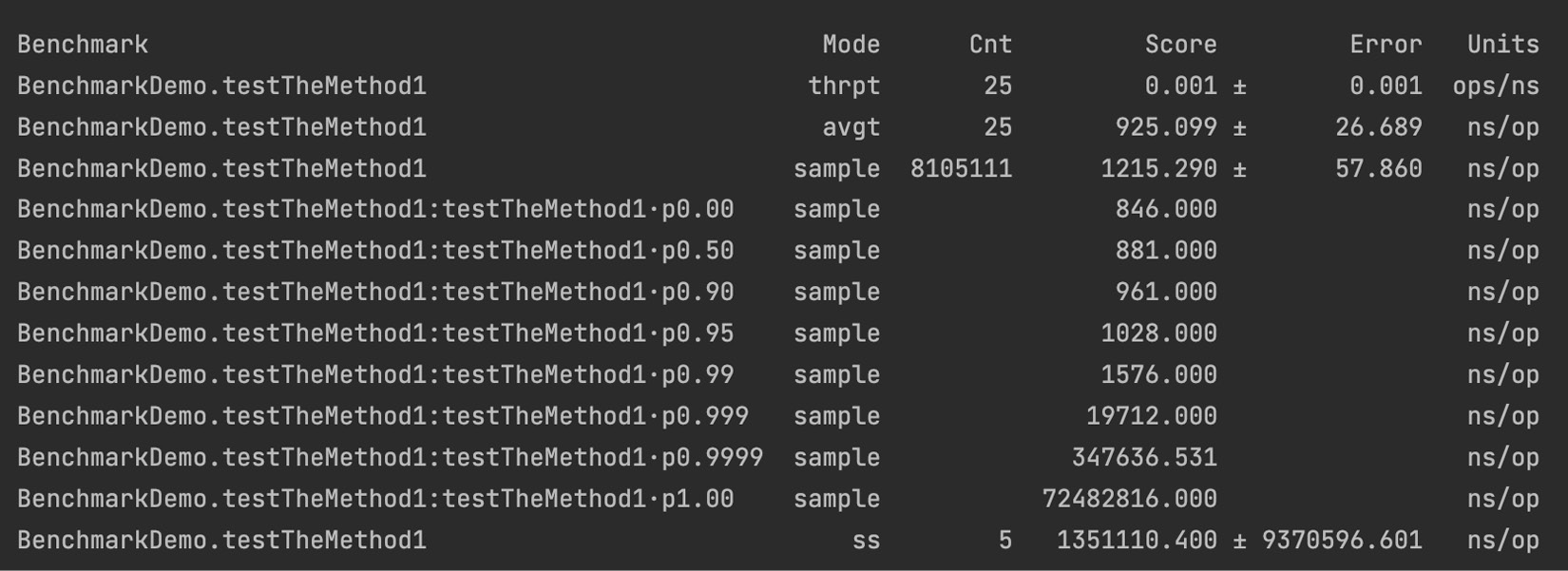
结果在采样和单次运行方面大多不同。您可以使用这些方法并更改分叉和热身次数。
Using the @State annotation
此 JMH 功能 允许您从 JVM 隐藏数据的来源 从而防止死代码优化。您可以添加一个类作为输入数据的来源,如下所示:
Scope 值用于在测试之间共享数据。在我们的例子中,只有一个使用 TestCase 类对象的测试,我们不需要共享。否则,该值可以设置为 Scope.Group 或 Scope.Benchmark,这意味着我们可以添加setter到 TestState 类并在其他测试中读取/修改它。
当我们运行这个版本的测试时,我们得到了以下结果:

数据又改变了。请注意,平均执行时间增加了三倍,这表明没有应用更多的 JVM 优化。
Using the Blackhole object
此 JMH 功能 允许模拟结果使用,从而防止 JVM 实现折叠常量优化:
如您所见,我们刚刚添加了一个参数 Blackhole 对象并调用了 consume() 方法 ;在它上面,因此 假装 使用了测试方法的结果。
当我们运行这个版本的测试时,我们得到了以下结果:
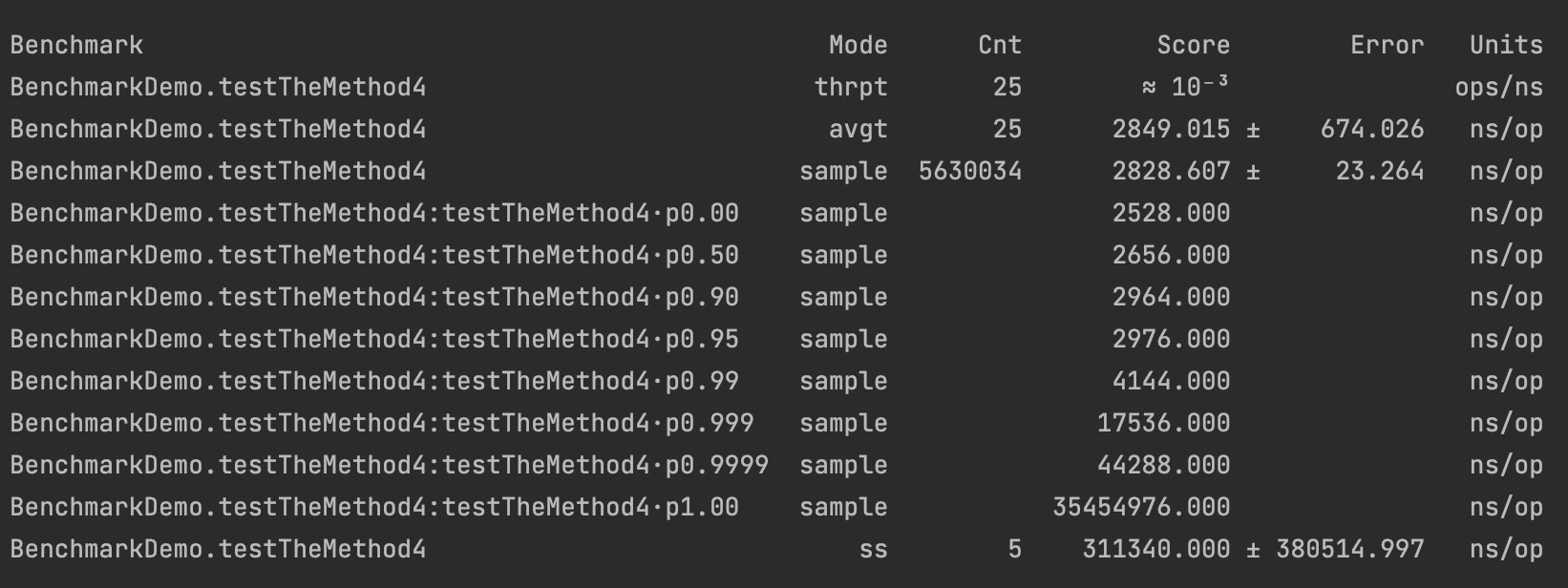
这一次,结果看起来并没有那么不同。显然,在添加 Blackhole 用法之前,常量折叠优化就被中和了。
Using the @CompilerControl annotation
调整基准的另一种方法是告诉编译器 编译、内联(或不内联)和排除(或不)代码中的特定方法。例如,考虑以下类:
假设我们对方法 anotherMethod() 编译/内联如何影响性能感兴趣,我们可以设置 CompilerControl mode 就可以了,如下:
Using the @Param annotation
有时,需要为不同的输入数据集运行相同的 benchmark 。在这种情况下, @Param 注解非常有用。
@Param 是各种框架使用的标准Java注解,例如JUnit。它标识一组参数值。带有 @Param 注解的测试将运行与数组中的值一样多的次数。 每次测试执行都会从数组中获取不同的值。
这是一个例子:
testTheMethod6() benchmark 是 going与每个列出的参数值 m。
A word of caution
所描述的线束消除了测量性能的程序员的大部分担忧。然而,几乎不可能涵盖 JVM 优化、配置文件共享和 JVM 实现的类似方面的所有情况,特别是如果我们考虑到 JVM 代码会随着一种实现的发展和不同的实现而不同。 JMH 的作者通过打印以下警告以及测试结果来承认这一事实:

探查器的描述及其用法可以在 openjdk 项目(http://hg.openjdk.java.net/code-tools/jmh /file/tip/jmh-samples/src/main/java/org/openjdk/jmh/samples)。在相同的示例中,您将遇到 JMH 基于注释生成的代码的描述。
如果您想真正深入了解代码执行和测试的细节,没有比研究生成的代码更好的方法了。它描述了 JMH 为运行所请求的基准测试所做的所有步骤和决策。您可以在 target/generated-sources/annotations 中找到生成的代码。
本书的范围不允许对如何阅读它进行过多的详细介绍,但这并不是很困难,尤其是如果您从一个简单的测试案例开始 一种方法。我们祝愿您在这项工作中一切顺利。
Summary
在本章中,您了解了 JMH 工具并能够将它用于您的应用程序。您已经学习了 如何创建和运行基准测试、如何设置基准测试参数以及如何在需要时安装 IDE 插件。我们还提供了实用的建议和参考资料以供进一步阅读。
现在,您不仅可以测量应用程序的平均执行时间和其他性能值(例如吞吐量),还可以以受控方式进行测量——无论是否有 JVM 优化、预热运行和很快。
在下一章中,您将学习设计和编写应用程序代码的有用实践。我们将讨论 Java习语,它们的实现和使用,并提供实现 equals(), hashCode()的建议code>、compareTo() 和 clone() 方法。我们还将 讨论 StringBuffer 和 StringBuilder 类的用法的区别, 如何捕获异常、最佳设计实践和其他经过验证的编程实践。
Quiz
- 选择所有正确的陈述:
- JMH 毫无用处,因为 它在生产环境之外运行方法。
- JMH 能够解决一些 JVM 优化问题。
- JMH 不仅可以测量平均性能时间 还可以测量其他性能特征。
- JMH 也可用于衡量小型应用程序的性能。
- 列出开始使用 JMH 所需的两个步骤。
- 说出 JMH 可以运行的四种方式。
- 列出可以与 JMH 一起使用(测量)的两种模式(性能特征)。
- 列出两个可用于呈现 JMH 测试结果的时间单位。
- 如何在 JMH 基准测试之间共享数据(结果、状态)?
- 您如何告诉 JMH 使用枚举值列表运行参数的基准测试?
- 如何强制或关闭方法的编译?
- JVM的不断折叠优化怎么关闭?
- 如何以编程方式提供 Java 命令选项以运行特定的基准测试?